
如何从RNN走向LSTM和GRU
为什么会出现LSTM和GRU呢?
因为 RNN 会出现梯度消失和梯度爆炸,梯度消失就意味着模型缺少长期记忆。
如果你问我为什么 RNN 会出现梯度消失,这是由它的训练公式决定的。
LSTM
这也解释了为什么 LSTM 多加了一条贯穿时间的,不直接施加任何权重的 cell state,就是为了解决梯度消失的问题,从而获取长期记忆。
理解了这一点,也许你再看 LSTM 的流程就会豁然开朗了,这边推荐油管上的一个视频 https://www.youtube.com/watch?v=YCzL96nL7j0,它甚至还举了一个计算的例子。
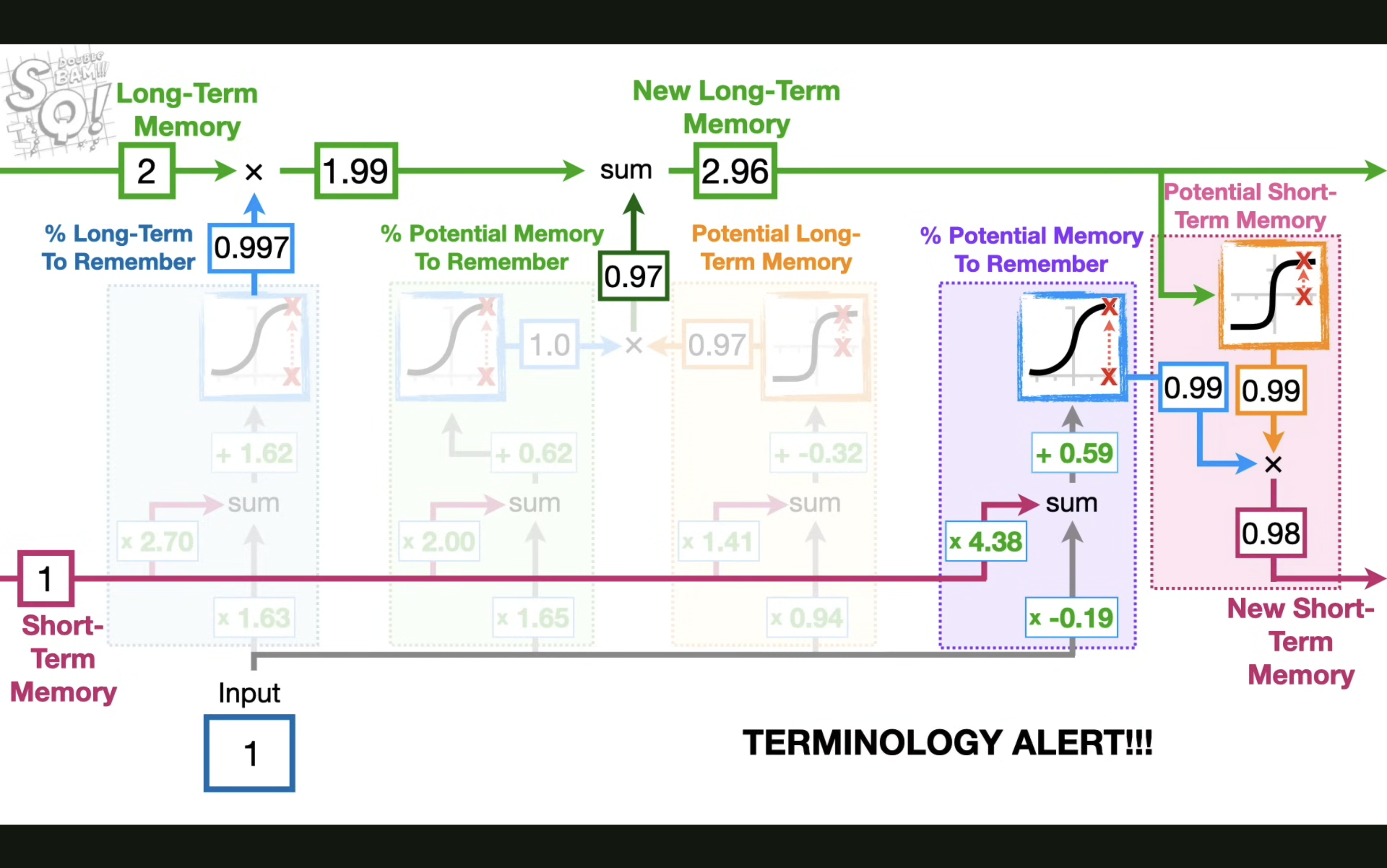
最后来解决最关键的问题:为什么 LSTM 是这样的结构?一个遗忘门,一个输入门,一个输出门?
本质其实就是在用最简单的模型模拟人的记忆过程,遗忘门决定了长期记忆里多少要被遗忘,输入门决定了新的记忆要加入多少,输出门决定了记忆的输出,同时这也是研究人员用各种参数和模型结构测试出来的结果。
切记不要神话任何模型的诞生,因为你只看到了最后的结果。
GRU
GRU 其实就是 LSTM 的简化版,它把遗忘门和输入门合并成了一个更新门,这样就减少了参数,也减少了计算量。
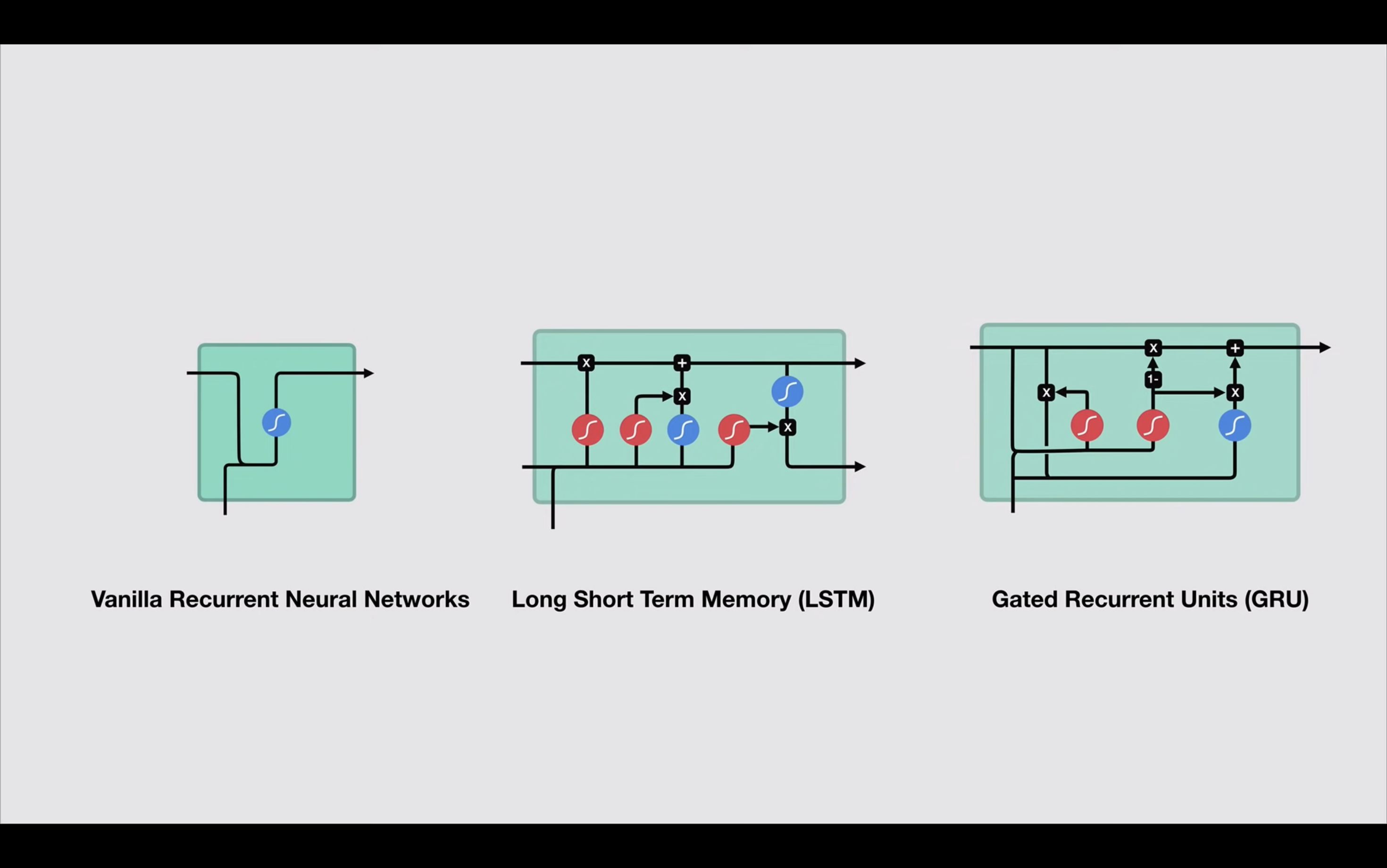
为什么这么做呢?
因为 LSTM 的参数太多,训练起来太慢,而且容易过拟合。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat alipay
alipay