
Uncertainty篇(三),用递归解遗传问题
前言上一篇说了要给大家用递归来解,昨天的那个算法太诡异了,接下来我们来讲一下,完整代码见 https://github.com/zong4/AILearning。
代码逻辑数据结构我这次用的是节点,如下,基本就是把表格信息都存下来了。
12345678910111213141516class Node: def __init__(self, name, father=None, mother=None, trait=None): self.name = name self.father = father self.mother = mother self.trait = trait ...# name,mother,father,trait# Harry,Lily,James,# James,,,1# Lily,,,0james = Node("James", None, None, True)lily = Node("Lily", None, None, False)h ...
Uncertainty篇(二),用隐式马尔可夫链解遗传问题
前言完整代码见 https://github.com/zong4/AILearning。
隐式马尔可夫链隐式马尔可夫链就是在马尔可夫链的基础上多了观察变量,如下图上半部分就是我们上一篇讲的马尔可夫链,具体可以阅读这一篇。
OK,那除此之外,在显式马尔可夫链中,我们是知道整个转移模型的(也就是上图的绿线),而在隐式马尔可夫链中我们只知道转移模型中的各状态对应传感器状态(也就是观察变量)的概率(也就是上图的红线)。
那自然我们除了之前的转移矩阵还有一个新的矩阵如下图所示。
于是我们就可以去计算各种情况的发生概率了。
不过大部分情况,我们之所以要用隐式马尔可夫链是因为我们不知道显式的马尔可夫链,比如下图的问题,对于这样的 笑脸 -> 笑脸 -> 苦脸 的顺序,天气的顺序最有可能是怎么样的?概率又是多少呢?
具体的计算思路就是类似于有记忆的递归算法,如下哦,这就不多说了吧,毕竟概率也是左加右嘛。
遗传问题OK,接下来就让我们来试着解一下遗传问题。
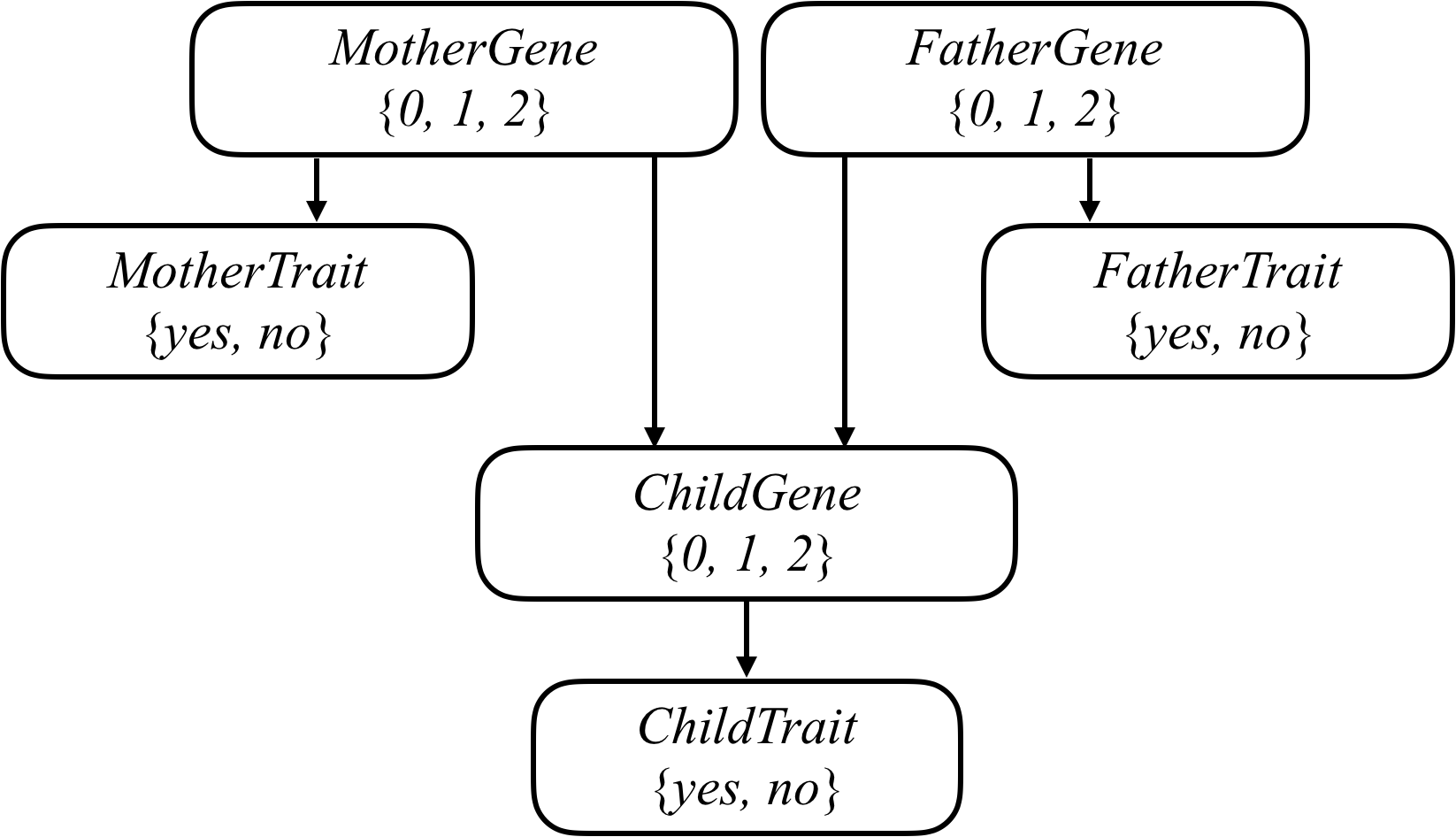
我们可以将任何遗传问题用下图表示。
超参数
来吧,首先是人群中(独立)携带指定基因的概率,用来算一开始第一步的概率,相当于初始 ...
Uncertainty篇(一),用马尔可夫链求PageRank
前言说实话,感觉也没什么好说的,都是大学概率统计学的内容,就挑重点讲一下吧,完整代码见 https://github.com/zong4/AILearning。
马尔可夫链马尔可夫链直白点说就是状态转移,如下图所示。
通过这样一个转移概率图,我们可以求出转移矩阵,类似下图。
通过这个矩阵,我们可以做很多事情,如下图,不过具体的还是来个实战吧。
Page RankPage Rank 就是用来评估网页的价值的(被更多网站引用的网站一般价值会更高)。
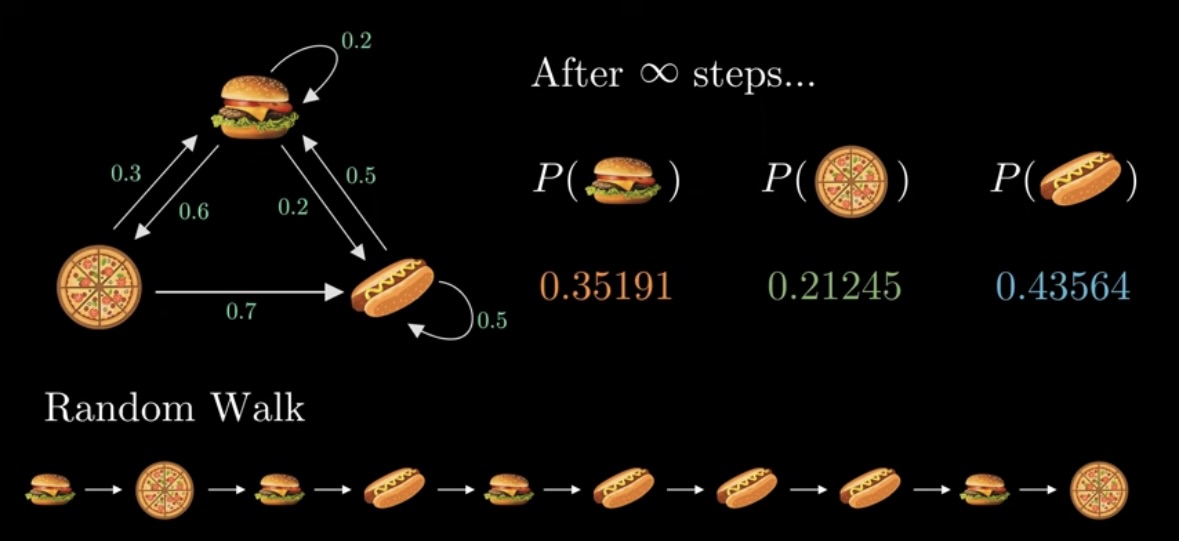
那我们这边主要用两种方法来计算,一种是随机冲浪者模型,另一种是迭代算法。
随机冲浪者模型这模型说白了就是在模拟大家平时浏览网站的操作。
假设大家随机从一个网站开始,当我们浏览完毕后,我们有一定概率(DAMPING)会去浏览它引用的其中一个网站,还有一定概率会重新再选一个网站浏览(1 - DAMPING)。
于是我们就可以写出如下代码。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556 ...

Knowledge篇(四),让AI玩狼人杀
前言终于,我们来玩狼人杀了,完整代码见 https://github.com/zong4/AILearning。
游戏规则规则的话,因为人越多越复杂,所以我这边就只弄了一个丐版的,五个人:三村民,一狼人,一预言,先给大家看一眼初始化游戏的代码。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859ROLES = ['citizen', 'werewolf', 'prophet']class Game: def __init__(self): number = 5 roles = {'citizen': 3, 'werewolf': 1, 'prophet': 1} players_name = ['player' + ...

Knowledge篇(三),让AI玩真假游戏
前言哎,狼人杀的逻辑好难实现,这毕竟不是大模型,给几个目标让他们自己练就可以,首先得我自己搞懂狼人杀的发言逻辑,所以今天还是先从比较简单的真假游戏开始,相信看完这篇,你也会和我一样眼前一亮,完整代码见 https://github.com/zong4/AILearning。
游戏规则同样的简单讲一下规则,这游戏我第一次接触是小学学奥数的时候。
简单来说,就是会有几个人,他们要么是骑士要么是恶魔,骑士只能说真话,而恶魔可以是假话也可以是真话,我们需要从他们说的话来判断他们的身份。
所以我们首先创建所有会用到的 Symbol。
12345678AKnight = Symbol("A is a Knight")AKnave = Symbol("A is a Knave")BKnight = Symbol("B is a Knight")BKnave = Symbol("B is a Knave")CKnight = Symbol("C is a Knight")CKnave = Symbol( ...
Knowledge篇(二),让AI玩扫雷
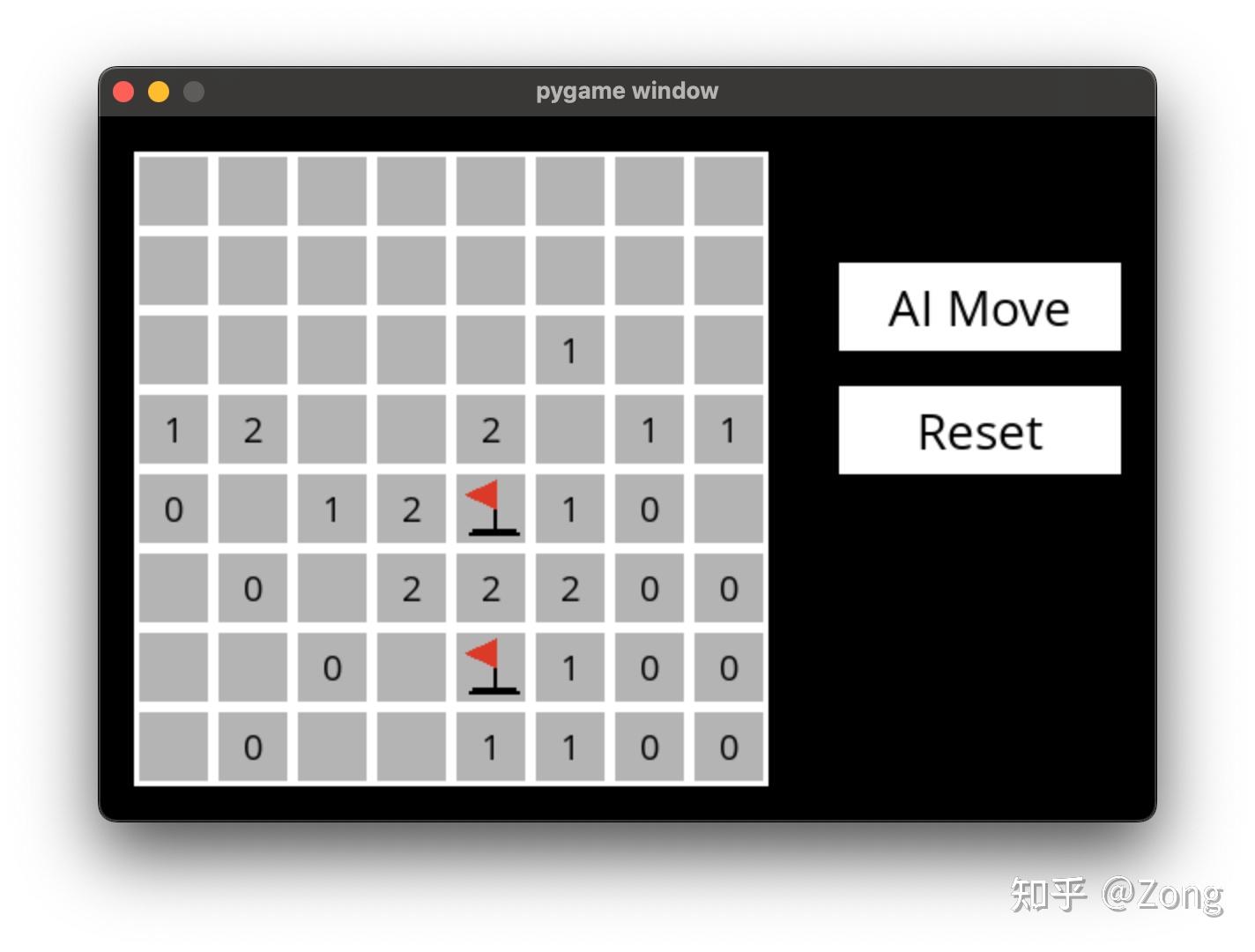
前言原本是要让 AI 来玩狼人杀的,后来感觉思路不是很清晰,所以干脆今天就先做个单人游戏——扫雷,先给大家看一下成果,完整代码见 https://github.com/zong4/AILearning。
游戏规则这里先给不了解游戏规则的人介绍一下游戏,扫雷中的每个数字代表的是,以此数字为中心的九宫格内有几颗地雷,如下图就表示 A~H 这八个格子里有一颗雷。
扫雷逻辑OK,那知道了游戏规则后,我们怎么来表示这个 Knowledge Base 呢?当然你可以像昨天说的那样用以下的式子来表示。
1Or(A, B, C, D, E, F, G, H)
但是,别忘了,上面的式子只能表达有至少一颗雷,但是没有表达出最多也只有一颗雷,具体还需要下面这一堆才行。
12345678910Or(And(A, Not(B), Not(C), Not(D), Not(E), Not(F), Not(G), Not(H)), And(Not(A), B, Not(C), Not(D), Not(E), Not(F), Not(G), Not(H)), And(Not(A), Not(B), ...

Knowledge篇(一),让AI具有逻辑
前言完整代码见 https://github.com/zong4/AILearning。
定义所谓的 Knowledge 就是指逻辑推理。
就像经典的苏格拉底三段论一样。
结构一个完整的可以分成什么呢?
Proposition Symbols这里的 Symbols 是指一句完整的有主谓宾的句子。
看一下代码吧,这块感觉没什么好讲的,不懂再说吧。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546class Sentence: def evaluate(self, model): raise NotImplementedError def formula(self): return "" def symbols(self): return set() @classmethod def validate(cls, sentence): if not ...
Search篇(二),让AI玩井字棋
前言完整代码见 https://github.com/zong4/AILearning。
零和博弈游戏正如之前所说,零和博弈中的最优解不是让自己来最多的分,而是让对方拿的分更少,换言之就是保证自己最坏情况下拿的分更多。
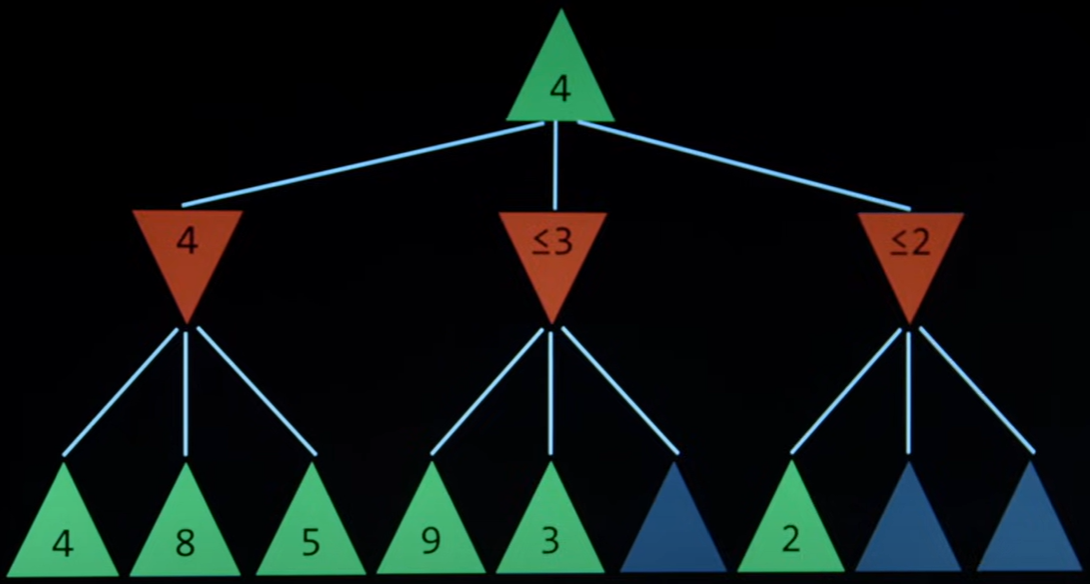
如下图,在目前的情况下,假设你(绿色玩家)下一手(上三条线),红色玩家下一手(下九条线),就达到了解空间中的其中一个状态,对应你获得的分数如下。
线是 Path,是 Transition Model。
作为绿色玩家,你应该考虑到红色玩家不会让你得最高的分,只会让你得最少的分。
因此,你此时的三种选择对应的分数分别是 min(4, 8, 5),min(9, 3, _) 和 min(2, _, _),那么目前状态下你可以获得的最高分数就是 max(4, $\leq$ 3, $\leq$ 2) = 4。
这也就是 MiniMax 的由来,来实现一下简单的井字棋。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849def minimax( ...
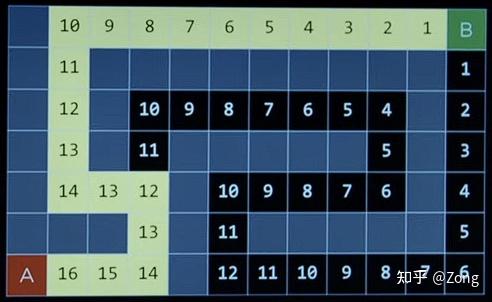
Search篇(一),让AI走迷宫
前言完整代码见 https://github.com/zong4/AILearning。
定义所谓 Search 就是寻找最优解。
生活中的话像导航,或者之前比较火的 AlphaGo 下围棋都算,我们就从比较有代表的迷宫开始。
Maze顺带一提,之前做雅思,好像 amaze 就是从 maze 延申出来的。
每一个 Maze,或者说每一个 Search 问题都能被分成以下几个部分。
Agent或者说 Player,如果是导航,那 Agent 就是你自己,如果是博弈游戏,那就是参与游戏的每个人。
Initial State同样的,如果是导航那就是你的起点,如果是围棋,那就是空棋盘。
Actions被规则允许的所有 Action。
Transition Model123def Result(State, Action): ... retun state
State Space没什么好说的,状态转移图。
可以被简化成有向图。
Goal Test没什么好说的,不然连解出来了都不知道。
Path Cost Function不同问题中的 Path Cost 是不一样的,可能是时 ...

基础篇
前言好久没更新了,之后尽量日更,最近在 gap,下半年去北欧读研,最近就随便学点感兴趣的东西。
我会尽量研究的透彻点,到研一的 level 吧(hope),代码基本都会附,但不会给全,不然你们都不思考。
定义Artificial Intelligence模拟人类的行为来解决问题。
Machine Learning和传统算法的区别在于目的是发现规律(Rules),和不是获取结果。
Deep Learning / Neural Networks相比于 ML,多了很多中间层。
NN 不是模拟人脑。
路线分成 Search,Knowledge,Uncertainty,Optimization,Learning,Neural Networks 和 Language 七个 Part 来理解 AI。
参考资料Harvard CS50’s Artificial Intelligence with Python – Full University Course
Machine Learning with Python Certification | freeCodeCamp.org
以及 ...