
如何从RNN走向LSTM和GRU
为什么会出现LSTM和GRU呢?因为 RNN 会出现梯度消失和梯度爆炸,梯度消失就意味着模型缺少长期记忆。
如果你问我为什么 RNN 会出现梯度消失,这是由它的训练公式决定的。
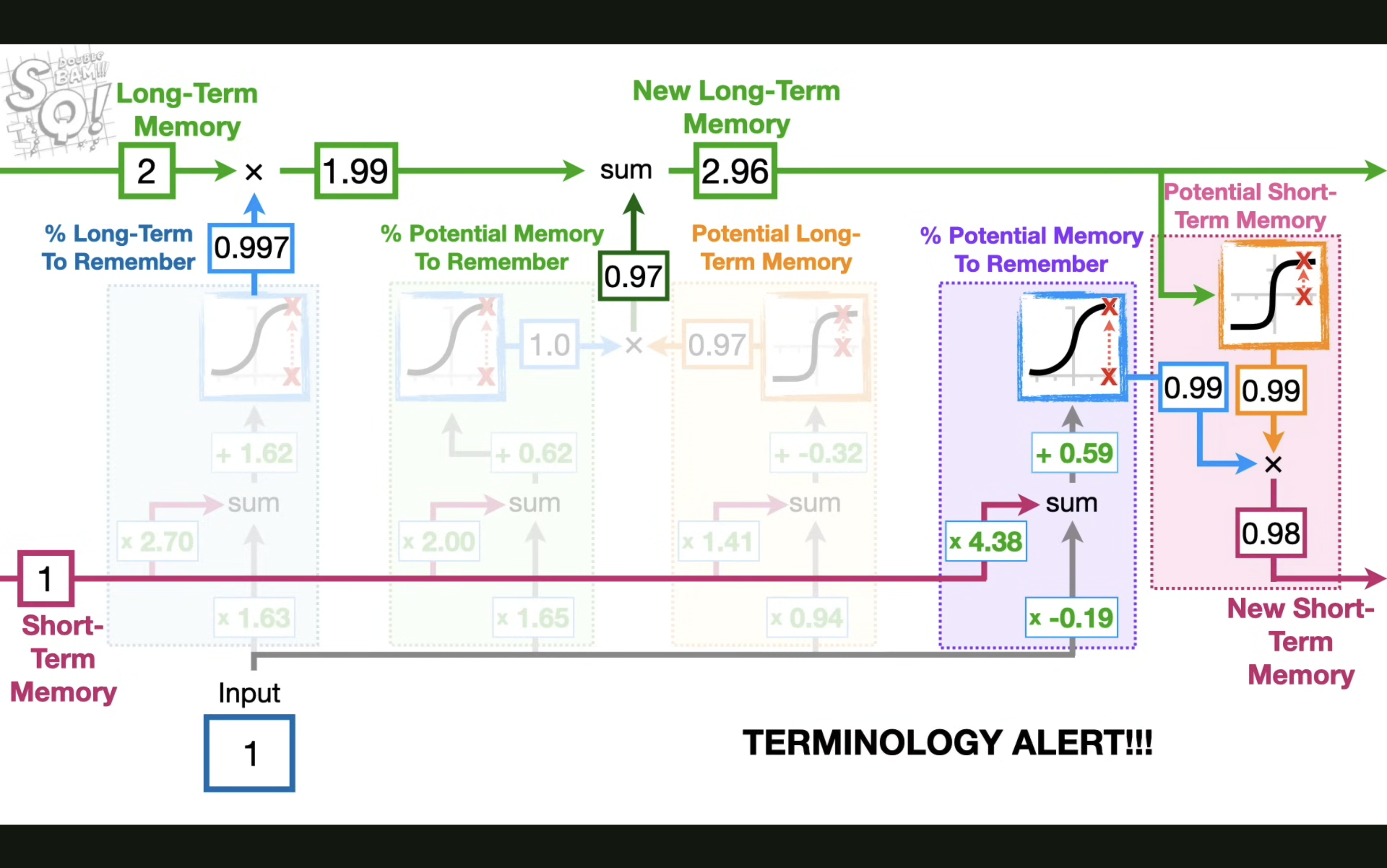
LSTM这也解释了为什么 LSTM 多加了一条贯穿时间的,不直接施加任何权重的 cell state,就是为了解决梯度消失的问题,从而获取长期记忆。
理解了这一点,也许你再看 LSTM 的流程就会豁然开朗了,这边推荐油管上的一个视频 https://www.youtube.com/watch?v=YCzL96nL7j0,它甚至还举了一个计算的例子。
最后来解决最关键的问题:为什么 LSTM 是这样的结构?一个遗忘门,一个输入门,一个输出门?
本质其实就是在用最简单的模型模拟人的记忆过程,遗忘门决定了长期记忆里多少要被遗忘,输入门决定了新的记忆要加入多少,输出门决定了记忆的输出,同时这也是研究人员用各种参数和模型结构测试出来的结果。
切记不要神话任何模型的诞生,因为你只看到了最后的结果。
GRUGRU 其实就是 LSTM 的简化版,它把遗忘门和输入门合并成了一个更新门,这样就减少了参数,也减少了计算量。
为 ...
深度学习的本质
前言要想讲清楚深度学习的本质,就要先从显示编程和隐式编程开始讲起。
显示编程所谓显示编程,顾名思义,就是咱们让计算机干什么,计算机就干什么,比如让计算机走迷宫,我们就是让它上下左右都试探一边。
123456def solve(maze): while not at_end(maze): for direction in ['up', 'down', 'left', 'right']: if can_move(maze, direction): move(maze, direction) break
隐式编程隐式编程其实就是指人工智能中的那些学习方法,它就是由机器学习之父提出来的,旨在不通过显示的告诉计算机怎么做,就能让计算机自己学会怎么做。
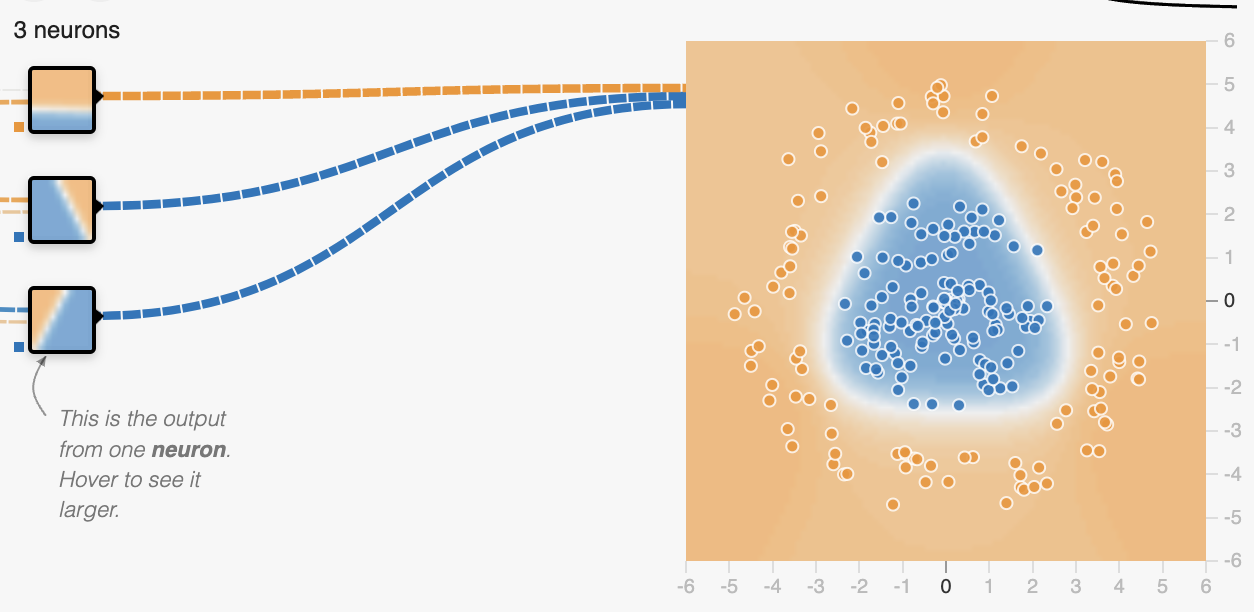
机器学习为了方便理解,所以我这里只讨论线性回归的方案,线性回归从本质上来说就是只有输入层和输出层的神经网络。
深度学习深度学习的提出其实就是为了让机器学习在特征提取时 ...
Pytorch神经网络训练全流程
数据预处理直接给大家看代码吧,完整代码在这 https://github.com/zong4/Kaggle,functions 的那些函数干了什么基本也就是字面意思(剔除一些没用的列然后归一化,再把字符串列进行one-hot编码)。
12345678910111213141516171819202122232425262728293031323334353637383940414243# Load dataimport sysimport pandas as pdbasic_path = 'house-prices-advanced-regression-techniques'train_data = pd.read_csv(basic_path + "/train.csv")test_data = pd.read_csv(basic_path + "/test.csv")# Prepare environmentimport functions_pytorchfunctions_pytorch.set_seed(42)# E ...

Xavier初始化
定义Xavier 初始化是一种比较常用的初始化方法,其核心思想是使得每一层的输出方差尽量相等,这样可以避免梯度消失和梯度爆炸,具体的公式如下。
$$W \sim U(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}})$$
其中 $n_{in}$ 是输入神经元的个数,$n_{out}$ 是输出神经元的个数,$U(a, b)$ 是均匀分布。
优点为什么要让每一层的输出方差尽量相等呢?
避免梯度消失和梯度爆炸:如果各层输出的方差不一致,可能会导致梯度在传递过程中逐渐变小(梯度消失)或逐渐变大(梯度爆炸)。
保证信号的有效传播:如果各层输出方差不一致,可能会导致信号在某些层被放大或缩小,从而影响网络对特征的提取和学习能力。例如,当某一层的输出方差过大时,该层的输出值可能会超出激活函数的有效范围,使得激活函数饱和,从而丢失了部分信息。
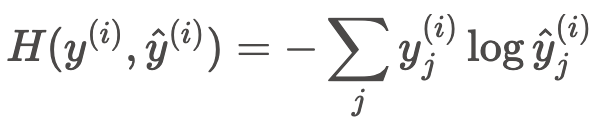
交叉熵损失函数的前世今生
前言西瓜书基本都过了一遍,感觉怎么说呢,理论气息太重了,实战中的价值感觉不大,所以我又开了一本新书《动手学深度学习》,之后就是边看边把自己觉得重要和有所感悟的地方记录下来。
交叉熵损失函数先来看看交叉熵损失函数长啥样,
$$H(y^{(i)}, \hat{y}^{(i)}) = -\sum_{j} y_j^{(i)} \log \hat{y}_j^{(i)}$$
其中 $p(x)$ 是真实分布,$q(x)$ 是预测分布,$j$ 是标签类别的索引。
不知道大家看到这个会不会觉得很熟悉,反正我第一时间就想到了信息熵。
信息熵同样的我们也来看看信息熵长啥样。
$$H(p) = -\sum_{x} p(x) \log p(x)$$
其中 $p(x)$ 是概率分布。
是不是几乎一摸一样,所以交叉熵损失函数的本质就是在求预测分布所包含的信息量。
那为什么要最小化交叉熵损失函数,也就是最小化信息量呢?
因为信息量越小,意味着信息越纯净,大家可以画一下上面的函数图,会发现当且仅当 $y^{(i)} = \hat{y}^{(i)}$ 时,交叉熵损失函数取最小值,也就是说预测 ...
决策树,处理缺失值
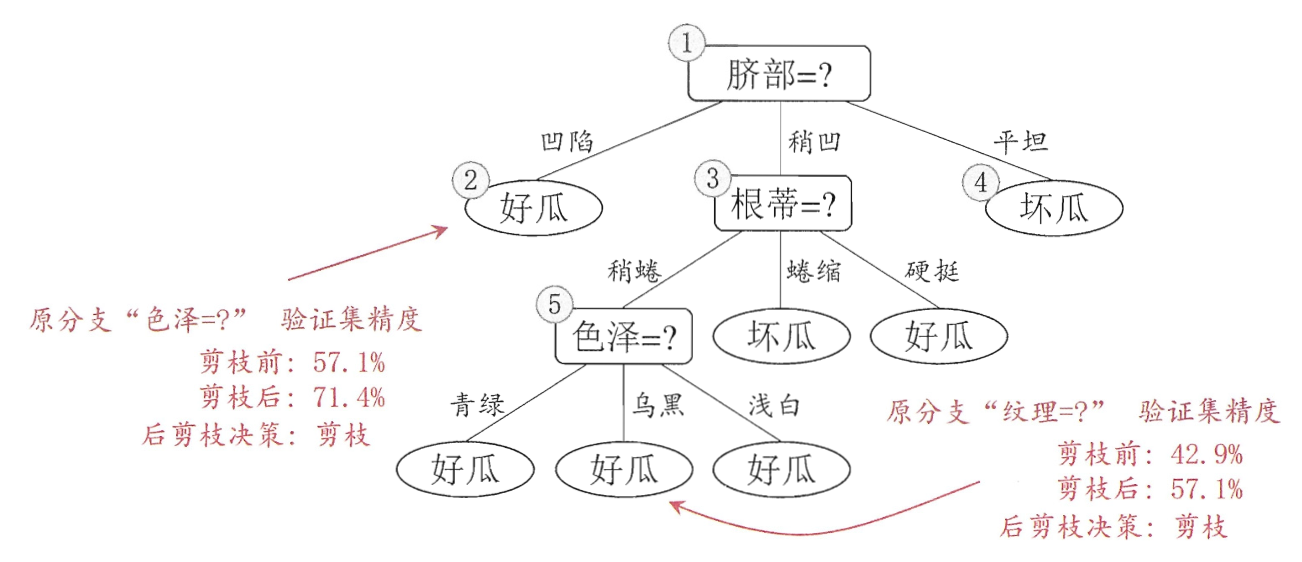
前言像基本流程,划分选择,剪枝处理,我这边就不讲了,直接看后面的重点。
缺失值处理我之前一直以为决策树是不能处理缺失值的,所以我之前那篇集成学习才会自己实现随机森林的缺失值处理,这次给大家看看能处理缺失值的决策树。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879class DecisionTreeClassifierWithMissing(DecisionTreeClassifier): def _split_node(self, X, y, sample_weight, depth, impurity, n_node_samples, weighted_n_node_samples, feature, threshold): left_indices = [] ri ...
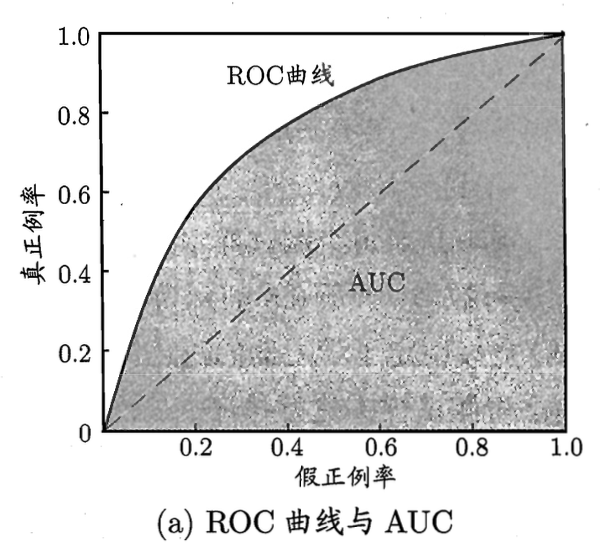
模型评估与选择,理解AUC和ROC
前言我总是觉得,光看书很难理解知识,因为人们在写书时似乎总是把知识写得很官方,全然不讲那些知识是如何被想出来的。
AUC从咱们的定义上来说,这就是一条真正例率(TPR)和假正例率(FPR)的关系曲线。
至于这条线是怎么画出来的,就是通过不停的调整分类阈值,然后计算出每个阈值下的TPR和FPF。
所以其实在我眼里,y轴也可以被替换为分类阈值。
也就是说这本质上可以理解为一条假正例率关于分类阈值的变化曲线。
所以 AUC 的本质作用就是用来寻找合适的分类阈值。
那自然我们也可以根据我们的实际需要,比如真负例率(TNR)更重要,那么我们就可以画出另一条 ”AUC“(到时候就不叫这个名字了),来帮助我们挑选合适的分类阈值。
ROCROC 呢其实没太多需要解释的,看书就行了。
被包裹了自然就说明另一个模型更好,毕竟假正例率一样的时候,真正例率更高的模型自然更好。
但是要是说面积更大的模型更好,那我就不敢苟同了,毕竟你模型提交上去的时候阈值就定下来了。
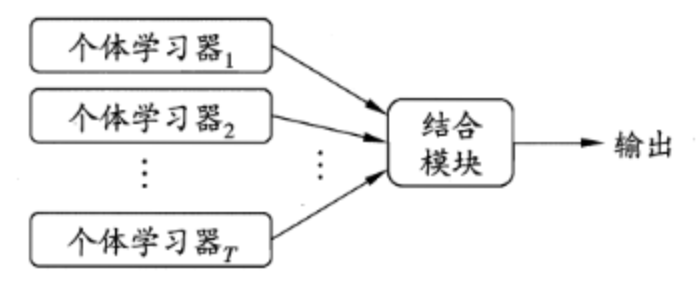
集成学习,改良随机森林算法,预测缺失数据集
前言这个专栏的核心是阅读《机器学习》这本书,同时也会结合 Kaggle 等实战项目,加深对机器学习的理解。
这次是第8章,集成学习,用 Kaggle 的泰坦尼克号生存预测来举例,代码见 https://www.kaggle.com/code/zzoonngk/titanic。
定义集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等,一般可以被简化为如下结构。
其中这些个体学习器可以用相同的算法,也可以用不同的算法。
那么集成学习是如何做到比单个学习器更好的呢?来看一组图。
这里默认的结合方法是“少数服从多数”,可以发现只有情况a可以集成提升性能。
基于此,我们可以得出集成个体应该“好而不同“,如果大家不好就可能会是情况c,如果大家都好但是一样就可能会是情况b。
由此引申出了个体学习器的准确性与多样性。
BoostingBoosting 是一种串行集成学习方法,核心思路是不断提高个体学习器的准确性。
...
Language篇(三),让AI识别垃圾邮件
前言今天是最后一个 Project 了,完整代码见 https://github.com/zong4/AILearning。
词袋模型(Bag-of-Words)之前的文章有提到词袋模型做垃圾邮件分类效果挺好的,所以先用这方法,核心代码如下。
1234567891011# 提取特征vectorizer = CountVectorizer()X_train = vectorizer.fit_transform(train_data['message'])X_test = vectorizer.transform(test_data['message'])y_train = train_data['label']y_test = test_data['label']# 训练模型model = MultinomialNB()model.fit(X_train, y_train)
构建词汇表遍历训练集中的所有邮件文本,统计出现的所有不重复的词汇,这些词汇构成了词汇表(Vocabulary)。
例如,训练集中的邮件 ...
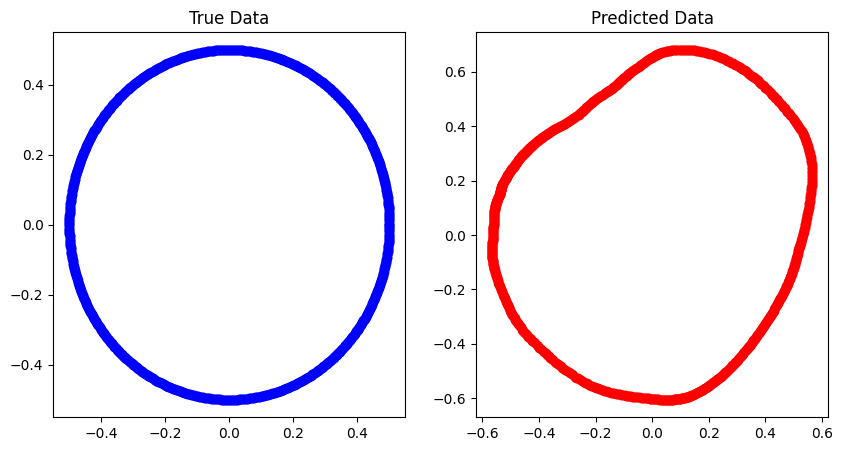
Neural Networks篇(三),用无监督学习让AI学会画圆
前言之前不是有说过,神经网络可以学会非线性关系,例如圆之类的,今天我们就来尝试一下,目标就是拟合出下面的圆,完整代码见 https://github.com/zong4/AILearning。
无监督学习大家先自己过一下代码。
12345678910111213141516171819202122232425262728293031323334353637# 生成圆上的数据点num_points = 1000theta = np.linspace(0, 2 * np.pi, num_points)radius1 = 1radius2 = 2x1 = radius1 * np.cos(theta)y1 = radius1 * np.sin(theta)x2 = radius2 * np.cos(theta)y2 = radius2 * np.sin(theta)data = np.column_stack((np.concatenate((x1, x2)), np.concatenate((y1, y2))))# 划分训练集和测试集train_size = int(0.8 * num_ ...