
DX12渲染管线学习笔记
前言
零散的笔记,是我在学习过程中的思考,自认为简单的东西并不会记录在内。
Direct3D 基础
初始化 D3D
Factory 和 Device
说实话 DirectX 中的架构思路真的值得去学习,这里的工厂和驱动都是蕴含了很多的设计思想的,但我目前还不能真正的理解。

WRAP
应该不需要去写它的意义吧,猜猜就知道了。
命令
个人感觉 CommandList 类似于资源描述符,而 CommandAllocator 类似于缓冲区,将 CommandList 中的命令传入 CommandQueue 中,但是 CommandAllocator 还是原来的,这也是为什么在 CommandQueue 的命令被执行完前不能重置 CommandAllocator。
渲染流水线
目前这里指的就是普通的光栅化流水线。
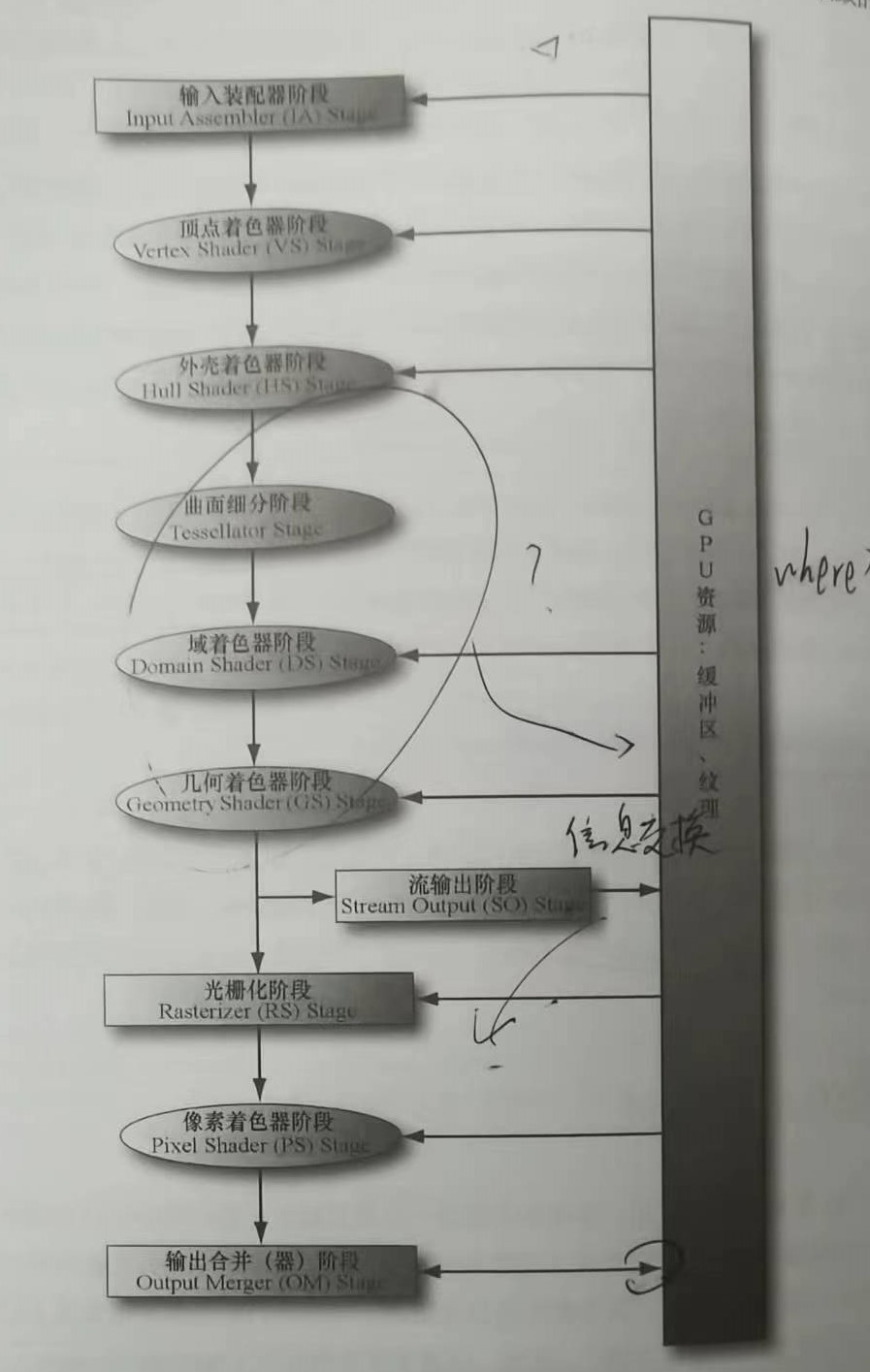
这里特地拍了一张我在书上的笔记,是想展示一下数据的流向。
Step1 内存数据流向显存
可以先到后面看一下流水线状态,可以发现主要就是绑定根签名表和 Shader,缓冲区都是在创建时绑定的,当然绑定的都是描述符,绑定数据的话带宽直接废掉了。

书里也说得很清楚了绑定的时候 GPU 会自动创建描述符和堆,GPU 会在需要用到数据的时候将数据存入显存中(闲时存入,减少带宽消耗)。
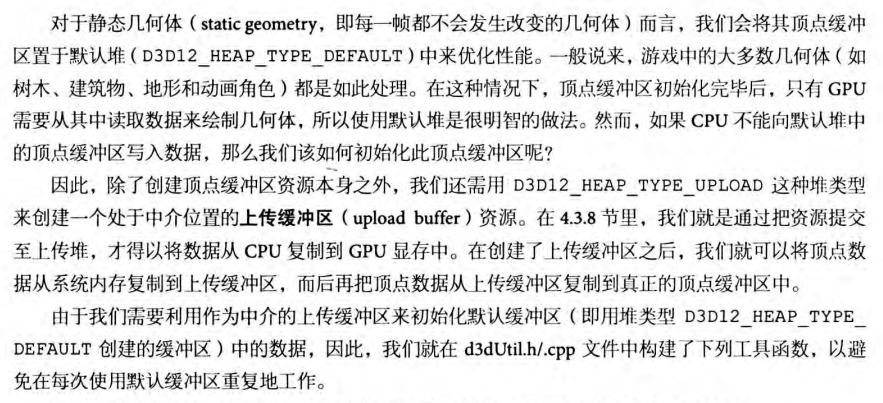
Vertex Buffer、Index Buffer 和 Constant Buffer 的创建与提交在第六章都有详细介绍,阅读之前一定要对描述符、视图、描述表以及描述堆等名词有足够的理解。
关于为什么 RTV 不用绑定,个人认为应该是直接封装在 CreateRenderTargetView 里了。
Step2 显存数据流向显存
由于在曲面细分阶段、域着色阶段和几何着色阶段中,顶点数据会被扩展,所以要把新数据加入显存中,之后再提出来着色。
这也是传冲渲染管线相较于 Mesh Pipeline 的缺点。
Step3 显存数据流向显存
这里主要是像比如将光照存入纹理中这样的操作,就需要把纹理存在显存中,以便后续的使用。
Step4 显存数据流向内存
说实话也不一定是流向内存,可能只是放在了全局显存里,让 CPU 自己去读取。
关于对显存中数据的驻留,DX12 也是提供了底层的 API 供程序员主动管理,但是龙书中并没有说明具体的操作方法,详细的资料可以阅读《Residency(驻留)》或者去看官方的 API,这应该能带来不小的优化。
 wechat
wechat alipay
alipay