集成学习,改良随机森林算法,预测缺失数据集 | Word count: 1.8k | Reading time: 6min | Post View:
前言 这个专栏的核心是阅读《机器学习》这本书,同时也会结合 Kaggle 等实战项目,加深对机器学习的理解。
这次是第8章,集成学习,用 Kaggle 的泰坦尼克号生存预测来举例,代码见 https://www.kaggle.com/code/zzoonngk/titanic。
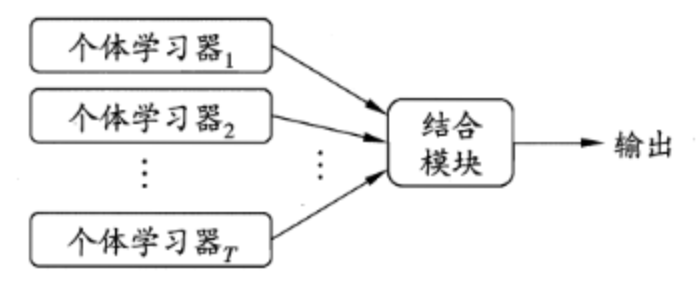
定义 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等,一般可以被简化为如下结构。
其中这些个体学习器可以用相同的算法,也可以用不同的算法。
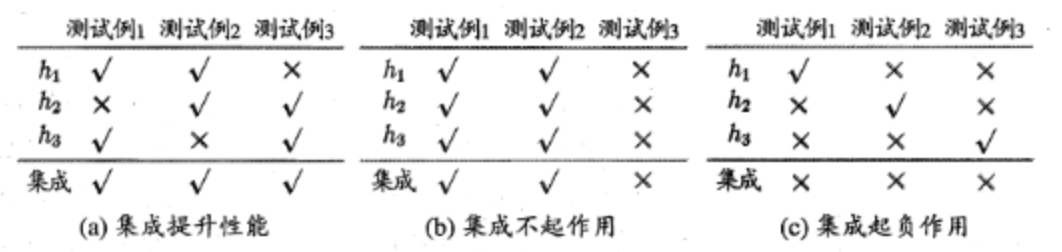
那么集成学习是如何做到比单个学习器更好的呢?来看一组图。
这里默认的结合方法是“少数服从多数”,可以发现只有情况a可以集成提升性能。
基于此,我们可以得出集成个体应该“好而不同“,如果大家不好就可能会是情况c,如果大家都好但是一样就可能会是情况b。
由此引申出了个体学习器的准确性 与多样性 。
Boosting Boosting 是一种串行集成学习方法,核心思路是不断提高个体学习器的准确性。
算法原理:先从初始训练集训练出一个基学习器,再根据基学习器的表现调整训练集,使得后续的基学习器更关注前面学习器分类错误的样本,最后将所有基学习器进行加权结合。
具体数学推导的话推荐大家去看书,我现在的水平也解释不太清楚。
Python 实现 AdaBoost 的话也不复杂,核心就这么几句。
1 2 3 4 base_estimator = DecisionTreeClassifier(max_depth=1 ) model = AdaBoostClassifier(estimator=base_estimator, n_estimators=100 , random_state=1 ) model.fit(X, y)
其中这里的基学习器是二层决策树,总共迭代学习100次,也就是说最后的预测结果是这100个学习器的加权和。
大家也可以试试换别的基学习器,我这边用了二层决策树(上面)和三层决策树(下面),结果如下。
可以发现在这个场景中,二层决策树的效果更好,猜测是在迭代过程中,三层决策树过拟合了,这也说明了为什么 Boosting 适合弱学习器。
Bagging 相比于 Boosting 在准确性上下功夫,Bagging 更关注多样性,那么如何实现多样性呢?
算法原理:通过随机采样训练集,训练出多个基学习器,最后将所有基学习器进行加权结合。
这里的采样方法是自助采样法(bootstrap sampling),即从训练集中有放回地采样出和原训练集一样大小的新训练集,最合大约有63.2%的样本被采样到。
实现代码都差不多,就换了个名字。
1 model = BaggingClassifier(estimator=base_classifier, n_estimators=100 , random_state=1 )
这次我比对了一下二层,三层,四层,发现三层的效果最好,同样是0.77511。
值得一提的是由于 Bagging 的采样方法,每个基学习器都是在不同的训练集上训练的,所以可以通过 OOB(Out-of-Bag)误差来评估模型的泛化能力。
OOB 误差是指在训练过程中,对于每个基学习器,都有一部分样本没有被采样到,这部分样本就是 OOB 样本,可以用来评估模型的泛化能力。
随机森林 相比于 Bagging 的样本多样性,随机森林又加了一条:特征多样性 。
算法原理:在 Bagging 的基础上,每次训练基学习器时,随机选择一部分特征训练决策树。
具体每次选几个特征,一般会选 log2(d) 个,其中 d 是特征总数,感觉log2确实是个很神奇的数。
但是决策树的深度毕竟不等于使用的特征数量,所以还是得自己测试。
结合策略 平均法/投票法 其实结合策略我看下来还是最普通的平均法/投票法比较好用,因为每个学习器的权重是比较难评估的。
我想这也是为什么即使再需要多样性,也不会让这些基学习器用不同的算法,因为这样就意味着必须得加权计算了。
学习法 除此之外就是学习法,有点类似于神经网络,具体思路是通过训练一个元学习器,来学习如何结合多个基学习器。
大家感兴趣的话可以自行研究,我感觉不如平均法/投票法来得直接,搞不好还会过拟合。
扩展 有随机森林,那就会有随机神经网络堆,大家可以自行研究,我这边就不展开了。
实战优化 最后来看一下实战,之所以正确率一直上不去,就是因为我们没有用那些虽然缺失了数据但是很重要的特征 。
所以我们可以改良随机森林,思路就是在训练时遇到缺失数据就剔除这个样本,预测时遇到缺失数据就用其他学习器的预测结果来投票。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 class ImprovedRandomForest : def __init__ (self, n_estimators=100 , max_depth=None , random_state=None ): self.n_estimators = n_estimators self.max_depth = max_depth self.random_state = random_state self.trees = [] self.used_features = [] def fit (self, X, y ): if isinstance (X, pd.DataFrame): numerical_cols = X.select_dtypes(include=[np.number]).columns boolean_cols = X.select_dtypes(include=[bool ]).columns X_numerical = X[numerical_cols].values X_boolean = X[boolean_cols].values if isinstance (y, pd.Series): y = y.values np.random.seed(self.random_state) n_samples, n_num_features = X_numerical.shape _, n_bool_features = X_boolean.shape all_features_count = n_num_features + n_bool_features for _ in range (self.n_estimators): feature_indices = np.random.choice(all_features_count, size=int (np.sqrt(all_features_count)), replace=False ) num_indices = [i for i in feature_indices if i < n_num_features] bool_indices = [i - n_num_features for i in feature_indices if i >= n_num_features] X_num_subset = X_numerical[:, num_indices] X_bool_subset = X_boolean[:, bool_indices] if num_indices: missing_mask_num = np.isnan(X_num_subset).any (axis=1 ) else : missing_mask_num = np.zeros(n_samples, dtype=bool ) missing_mask_bool = np.zeros(n_samples, dtype=bool ) missing_mask = missing_mask_num | missing_mask_bool if missing_mask.any (): X_num_clean = X_num_subset[~missing_mask] X_bool_clean = X_bool_subset[~missing_mask] X_clean = np.hstack((X_num_clean, X_bool_clean)) y_clean = y[~missing_mask] else : X_clean = np.hstack((X_num_subset, X_bool_subset)) y_clean = y tree = DecisionTreeClassifier(max_depth=self.max_depth) tree.fit(X_clean, y_clean) self.trees.append(tree) self.used_features.append(feature_indices) def predict (self, X ): if isinstance (X, pd.DataFrame): numerical_cols = X.select_dtypes(include=[np.number]).columns boolean_cols = X.select_dtypes(include=[bool ]).columns X_numerical = X[numerical_cols].values X_boolean = X[boolean_cols].values n_samples = X_numerical.shape[0 ] predictions = np.full((n_samples, self.n_estimators), np.nan) for i in range (self.n_estimators): feature_indices = self.used_features[i] num_indices = [idx for idx in feature_indices if idx < len (numerical_cols)] bool_indices = [idx - len (numerical_cols) for idx in feature_indices if idx >= len (numerical_cols)] for sample_idx in range (n_samples): sample_num = X_numerical[sample_idx, num_indices] sample_bool = X_boolean[sample_idx, bool_indices] has_missing = np.isnan(sample_num).any () if num_indices else False if not has_missing: sample = np.hstack((sample_num, sample_bool)).reshape(1 , -1 ) prediction = self.trees[i].predict(sample) predictions[sample_idx, i] = prediction[0 ] final_predictions = [] for row in predictions: valid_predictions = row[~np.isnan(row)] if valid_predictions.size > 0 : final_predictions.append(np.bincount(valid_predictions.astype(int )).argmax()) return np.array(final_predictions)

 wechat
wechat alipay
alipay