# function to return recommended books - this will be tested defget_recommends(book = ""): # create a new dataframe with the books and their ratings df = df_books.set_index('isbn').join(df_ratings.set_index('isbn')) # print(df.iloc[:4])
# create a nearest neighbors model model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20) model_knn.fit(df_pivot)
# get the index of the book query_index = df_pivot.index.get_loc(book) distances, indices = model_knn.kneighbors(df_pivot.iloc[query_index, :].values.reshape(1, -1), n_neighbors=6)
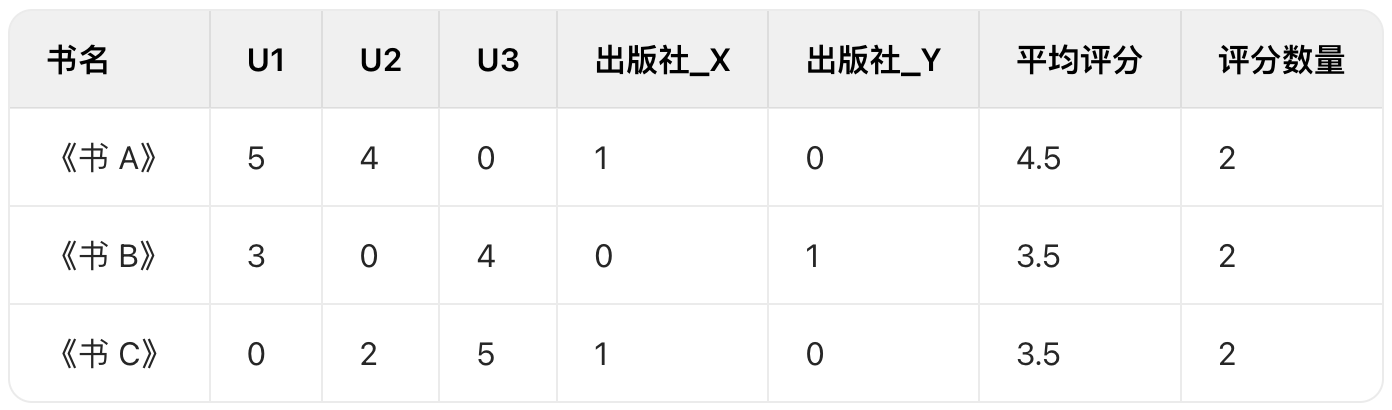
# average rating and number of ratings for each book average_rating = df_ratings.groupby('isbn')['rating'].mean() rating_count = df_ratings.groupby('isbn')['rating'].count() df_ratings_avg = pd.DataFrame({'isbn': average_rating.index, 'avg_rating': average_rating.values, 'rating_count': rating_count.values})
# create a new dataframe with the books and their ratings df = df_books.set_index('isbn').join(df_ratings_avg.set_index('isbn')) # print(df.iloc[:4])
# One Hot Encoding author_encoder = LabelEncoder() df['author_encoded'] = author_encoder.fit_transform(df['author'])
features = df[['author_encoded', 'year', 'publisher_encoded', 'avg_rating', 'rating_count']]
# create a nearest neighbors model model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20) model_knn.fit(features)
结果报错了。
1
ValueError: could not convert string to float: 'John Peterman'
优化2:数据清洗
看了一眼,就是书名有分号,所以识别出了问题。
加了一行这个没什么用,毕竟 mac 自带的 csv 读取器也错了,只能手改了。
1
quoting=csv.QUOTE_ALL
算了太多了,直接把数据丢了吧。
1 2 3 4 5
# create a new dataframe with the books and their ratings df = df_books.set_index('isbn').join(df_ratings_avg.set_index('isbn')) df = df[df['year'].str.isnumeric()] df = df.dropna() df['year'] = df['year'].astype(int)
输入是 “Where the Heart Is (Oprah’s Book Club (Paperback))”,结果还可以,找的都是同一个作者的书。
1 2 3 4 5 6 7 8
{ "Where the Heart Is (Oprah's Book Club (Paperback))": { "The Honk and Holler Opening Soon": 0.0004220216524539744, "Where the Heart Is: A Novel": 0.0004329866196861598, "Where the Heart Is": 0.00045208676755403854, "Shoot the Moon": 0.00047166440227597306 } }
不过感觉评分应该也不能加入相似性计算里,应该是找到了之后用评分排序比较好。
结果也是一样的,看来评分就没用,不过这相似度也太小了。
1 2 3 4 5 6 7 8
{ "Where the Heart Is (Oprah's Book Club (Paperback))": { "The Honk and Holler Opening Soon": 1.4160210781710703e-09, "Where the Heart Is": 5.6642790458028e-09, "Where the Heart Is: A Novel": 1.2744773680850585e-08, "Shoot the Moon": 5.097383926067067e-08 } }
试一下标准化。
1 2 3 4
# Standardization scaler = StandardScaler() features = df[['author_encoded', 'year', 'publisher_encoded', 'avg_rating', 'rating_count']] features = scaler.fit_transform(features)
结果也还是大差不差。
1 2 3 4 5 6 7 8 9
{ "Where the Heart Is (Oprah's Book Club (Paperback))": { "Christmas Words: See-And-Say Fun for the Very Young": 5.922528489854528e-08, "The Scold's Bridle": 7.66054157885776e-08, "The Void Captain's Tale": 3.051218466776362e-07, "An Album of Voyager": 8.988488962025087e-07, "This Old House : The Best of Ask Norm": 1.0828802619045064e-06 } }
# draw a bar chart of the number of books rated by each user ratings_per_user = df_ratings.groupby('user')['rating'].count() ratings_per_book = df_ratings.groupby('isbn')['rating'].count() logging.info("The distribution of ratings per book: ") logging.info(ratings_per_book.describe())
# average rating and number of ratings for each book average_rating = df_ratings.groupby('isbn')['rating'].mean() rating_count = df_ratings.groupby('isbn')['rating'].count() df_ratings_avg = pd.DataFrame({'isbn': average_rating.index, 'avg_rating': average_rating.values, 'rating_count': rating_count.values})
# train the knn model model_knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20) model_knn.fit(combined_data.values)
# function to return recommended books - this will be tested defget_recommends(book = ""): # get the isbn of the book isbn_index = df_books[df_books['title'] == book]['isbn'].values[0]
# get the index of the book in the combined data logging.info("Book: " + book) logging.info("ISBN index: ") if isbn_index notin combined_data.index: logging.info("Book not found.") return [] book_index = combined_data.index.get_loc(isbn_index)
distances, indices = model_knn.kneighbors(combined_data.iloc[book_index].values.reshape(1, -1), n_neighbors=5)
# the format of the recommended books # { # book: # { # [similar_book_1_isbn, similar_book_1_title]: distance_1, # [similar_book_2_isbn, similar_book_2_title]: distance_2, # [similar_book_3_isbn, similar_book_3_title]: distance_3, # [similar_book_4_isbn, similar_book_4_title]: distance_4, # [similar_book_5_isbn, similar_book_5_title]: distance_5 # } # } recommended_books = {} for i inrange(1, len(indices[0])): recommended_book_isbn = combined_data.iloc[indices[0][i]].name recommended_book_title = df_books.loc[df_books['isbn'] == recommended_book_isbn, 'title'].values[0] recommended_books[recommended_book_isbn + " "+ recommended_book_title] = distances[0][i]
return recommended_books
结果
还行,比之前好多了,就这样吧。
1 2 3 4 5 6
{ "042513699X Turtle Moon": 0.0026335611586064678, "0373825013 Whirlwind (Tyler, Book 1)": 0.00265084184906883, "0446365505 Pleading Guilty": 0.0026517030537067665, "0425150143 Tom Clancy's Op-Center: Mirror Image (Tom Clancy's Op Center (Paperback))": 0.0026543396062681524 }


 wechat
wechat alipay
alipay