# Strategy1: play the winning move of the opponent's last move if prev_play == 'R': return'P' elif prev_play == 'P': return'S' elif prev_play == 'S': return'R' else: return random.choice(['R', 'P', 'S'])
策略2
出能赢对手最容易出的那一手。
1 2 3 4 5 6 7 8 9
# Strategy2: play the winning move of the opponent's most frequent move if opponent_history.count('R') > opponent_history.count('P') and opponent_history.count('R') > opponent_history.count('S'): return'P' elif opponent_history.count('P') > opponent_history.count('R') and opponent_history.count('P') > opponent_history.count('S'): return'S' elif opponent_history.count('S') > opponent_history.count('R') and opponent_history.count('S') > opponent_history.count('P'): return'R' else: return random.choice(['R', 'P', 'S'])
# Function to run the simulation defrun_simulation(num_players_per_strategy, num_rounds): strategies = [always_cooperate, always_defect, tit_for_tat, random_choice] players = []
# Create players with equal distribution of strategies for strategy in strategies: for _ inrange(num_players_per_strategy): players.append(Player(strategy))
for round_num inrange(num_rounds): print("round_num: " + str(round_num))
random.shuffle(players) for i inrange(0, len(players), 2): if i + 1 < len(players): play_round(players[i], players[i + 1])
# Remove players with score <= 0 players = [player for player in players if player.score > 0]
always_cooperate_count = sum(1for player in players if player.strategy == always_cooperate) always_defect_count = sum(1for player in players if player.strategy == always_defect) tit_for_tat_count = sum(1for player in players if player.strategy == tit_for_tat) random_choice_count = sum(1for player in players if player.strategy == random_choice)
Round: 99 Always cooperate: 7 Always defect: 2 Tit for tat: 7 Random choice: 5 <function random_choice at 0x1029860c0> <function always_defect at 0x102987100> <function always_cooperate at 0x102986f20> <function tit_for_tat at 0x102986e80> <function always_cooperate at 0x102986f20> <function tit_for_tat at 0x102986e80> <function always_defect at 0x102987100> <function random_choice at 0x1029860c0> <function tit_for_tat at 0x102986e80> <function always_cooperate at 0x102986f20> <function always_cooperate at 0x102986f20> <function always_cooperate at 0x102986f20> <function always_cooperate at 0x102986f20> <function random_choice at 0x1029860c0> <function random_choice at 0x1029860c0> <function tit_for_tat at 0x102986e80> <function tit_for_tat at 0x102986e80> <function tit_for_tat at 0x102986e80> <function random_choice at 0x1029860c0> <function tit_for_tat at 0x102986e80> <function always_cooperate at 0x102986f20>
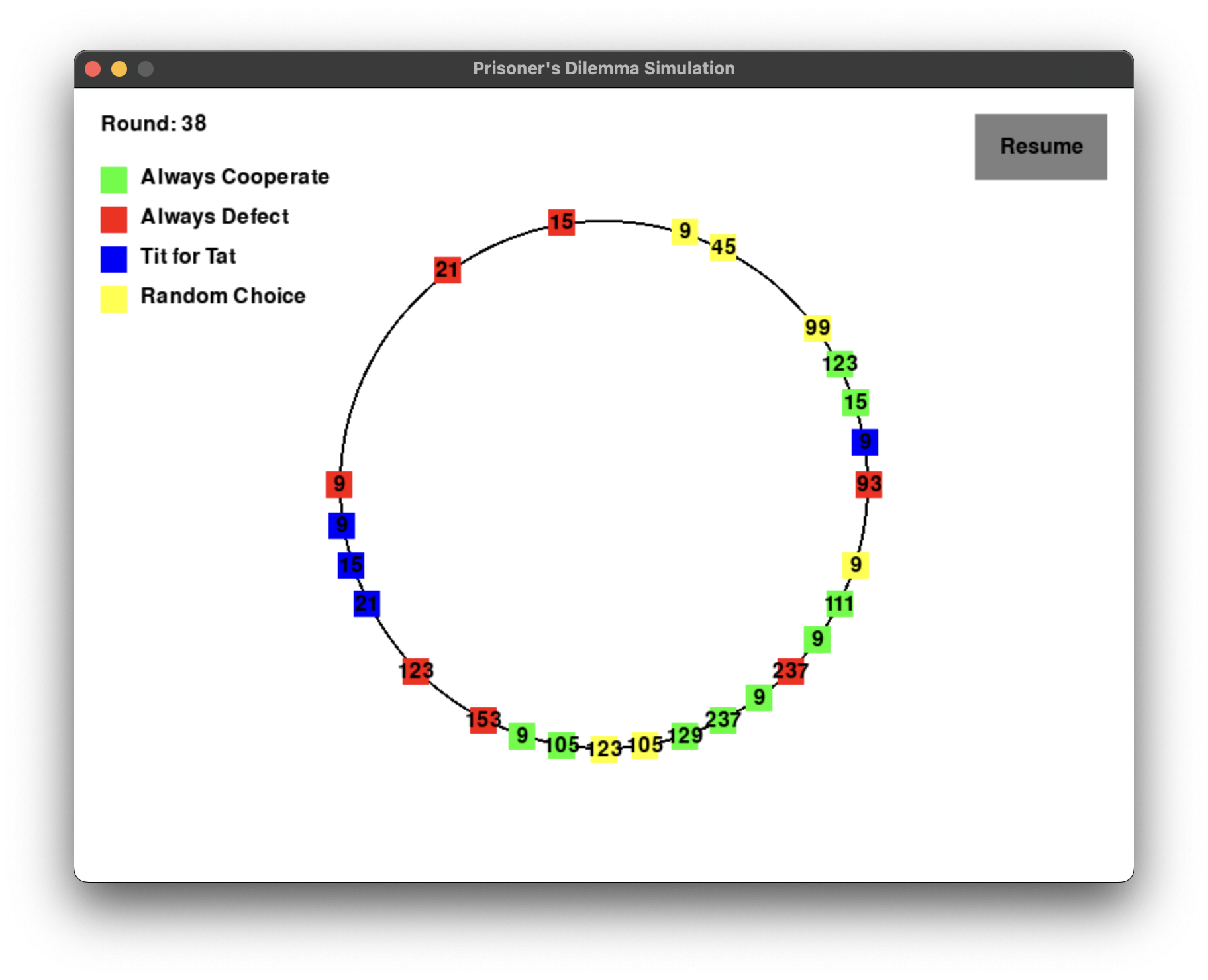
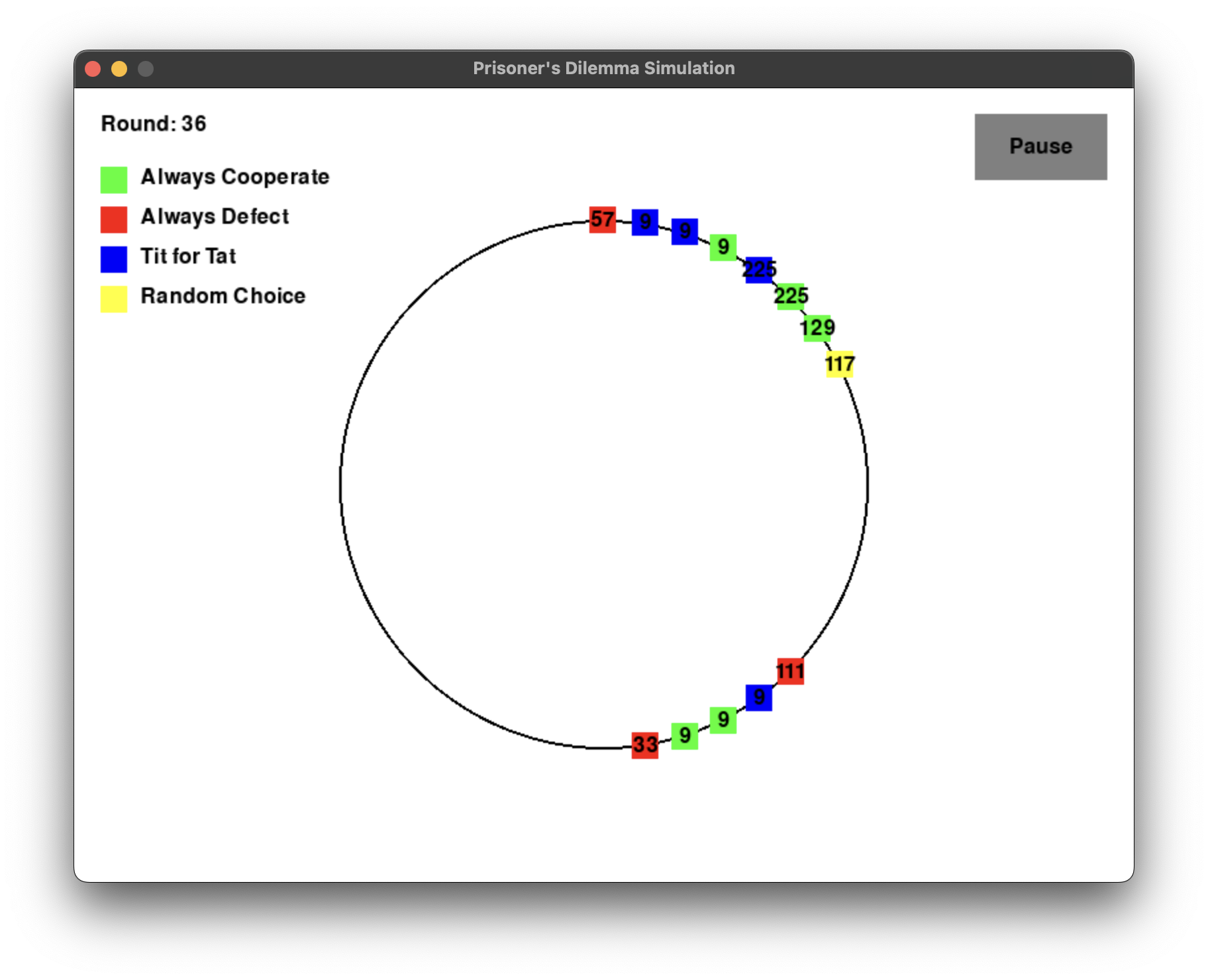
效果如下,看上去似乎还行,不过为了保险起见,先去掉随机者再观察一下。
改了一下,这次没问题了,看结果的话就是复读机和永远合作容易活,毕竟永远竞争会内部消耗,接下来就加个 AI 试试。
强化学习
仔细想了一下,好像没法让 AI 学策略,学出来也是跟随机者差不多估计,因为状态只有两个,学的也最多是一个不均等的选择概率。

 wechat
wechat alipay
alipay