
Language篇(二),生成并观察注意力热力图
前言
这是理论学习的最后一篇了,完整代码见 https://github.com/zong4/AILearning。
模型结构
序列模型
先来讲讲模型结构吧,如果你之前的文章有认真看,肯定会想到可以用处理序列输入和输出的模型结构。
首先将文本如下按序输入进去。
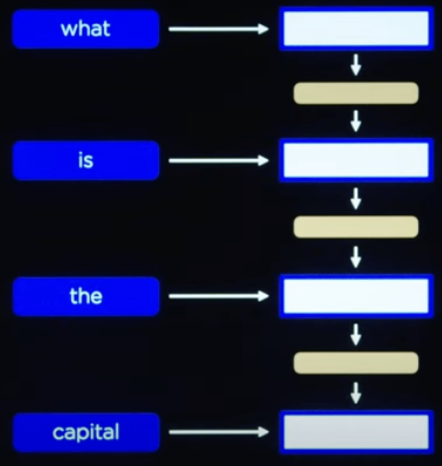
然后当输入到 [end] 符时就生成第一个输出词,然后再把输出的词按序输入,就能得到完整的输出。
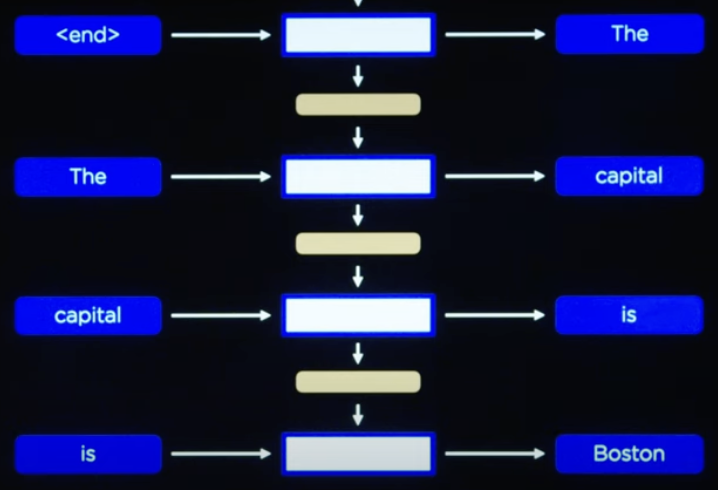
这样做确实可以,唯一的缺点就是不能并行,所以当数据量大的时候,消耗的时间和算力就会成倍上升。
Transformers
在 Transformers 中,我们可以做到让模型如下同时接收 Input 信息,然后处理生成 Output 信息。
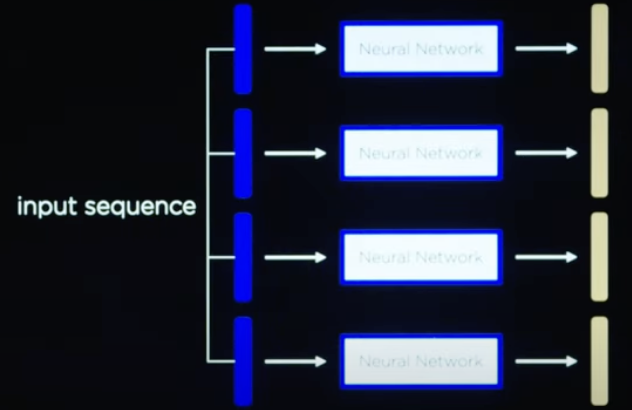
但是该有的信息还是一个都不能少,所以我们首先就得补充顺序信息,如下就是通过添加位置编码来实现的。
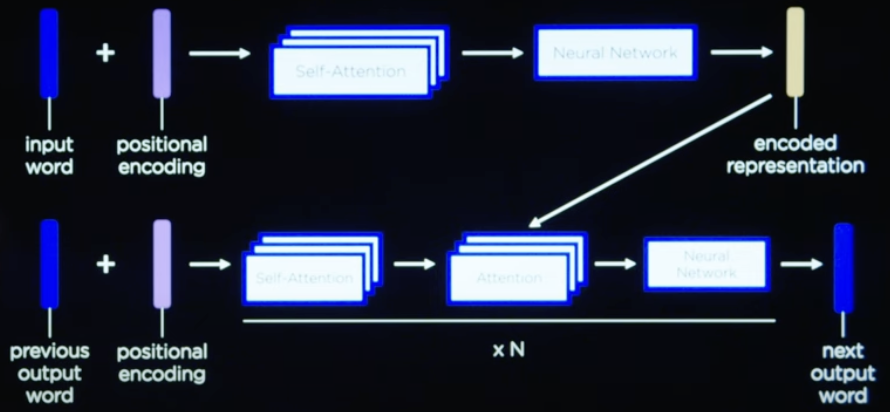
有了信息之后我们可以通过自注意力机制分析不同词之间的关联度,从而让模型更加专注于有价值的内容,如下图就是一张学会了顺序信息的注意力热力图。

那最后为了在输出的过程中,让模型知道自己之前输出了什么,就需要将之前的未解码的输出重新输入进来并计算交叉注意力。
注意力机制
原理和实现
关于注意力的原理我非常推荐大家看看3B1B的视频 https://www.youtube.com/watch?v=eMlx5fFNoYc,我这边就来带大家实现一遍,让大家看看注意力到底注意了什么东西。
主要给大家看一下主程序,因为都是调用,所以代码本身没什么难度,大家过一下就行。
1 | # Pre-trained masked language model |
结果
注意力层并不总是符合我们对单词之间特定关系的期望,它们也并不总是对应于人类可解释的关系,但我们可以根据它们看起来对应的东西进行猜测。
除了上面学到的顺序信息,注意力机制还可以学习到词性。
大家如果自己跑了一遍可以看看 Attention_Layer4_Head11 这张图(如下),可以看到它似乎发现了 moved 和 slowly 之间的联系。

我们尝试交换动词和副词的顺序,情况也是如此,即使有很多噪音。

因此,我们可以合理地猜测,这个注意力机制已经学会了注意副词和它们修饰的词之间的关系。
剩下的特性就由大家自行探索了,如果你懒得跑代码,可以看我上传的图片 https://github.com/zong4/AILearning/tree/main/attention。
后记
如此,这个专栏就到尾声了,狼人杀应该会鸽掉,因为它还需要大语言模型的支持才算完整,有点超纲了,所以这个专栏也会在这一篇结束。
明天可能会休息一天,然后开始为大家每周带来一篇最新的 AI 研究的复现,尽情期待。
 wechat
wechat alipay
alipay