
Language篇(一),让模型理解语法和语义
前言
哈哈哈,终于来到我的专业领域了,完整代码见 https://github.com/zong4/AILearning。
语法
大语言模型主要是需要解决两个问题,首先就是语法。
马尔可夫链
那其中一种解决方法我们之前试过了,没错,就是当时用马尔可夫链生成福尔摩斯故事。
它的本质就是通过每组词的转移概率来分析语法,同时也可以起到预测下一组词的作用。
上下文无关语法
除此之外我们也可以主动给 AI 提供语法,任何文本都可以用下面的语法树来表示。
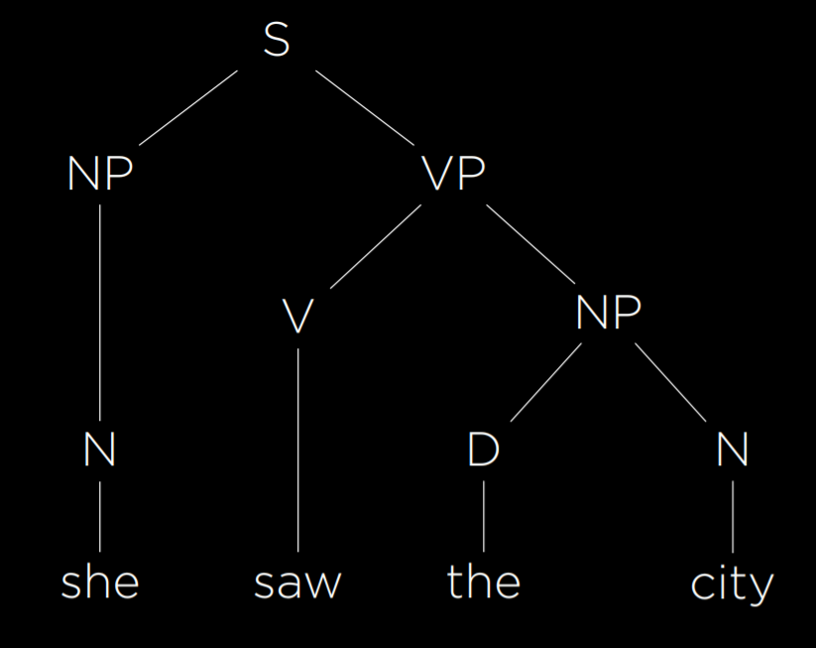
不过这棵比较简单,实际情况遇到长难句会非常复杂,给大家看一句。

我输入的语法模型是这样的,不知道有没有穷尽,但是至少也分析出来了。
1 | TERMINALS = """ |
语义
没有语义那么语言也就没有了灵魂,就像之前福尔摩斯的生成文章一样,看着好像说了很多,但其实什么也没说。
词袋模型
Bag-of-words 是一种将文本表示为无序单词集合的模型,此模型忽略语法,仅考虑句子中单词的含义。此方法在某些分类任务中非常有用,例如分类垃圾邮件。
具体的话就是说我这句话里正向词多就正向,负向词多情绪就是负向的。
那比如 ”我又开心又伤心“,那开心是正向,伤心是负向,正负各一个,这句话就是中性的了,除非我给某一个加个非常,很之类的。
朴素贝叶斯
朴素贝叶斯是一种可用于词袋模型的情绪分析的技术,对于一句话判断为某种情绪的概率我们可以用如下公式表示。
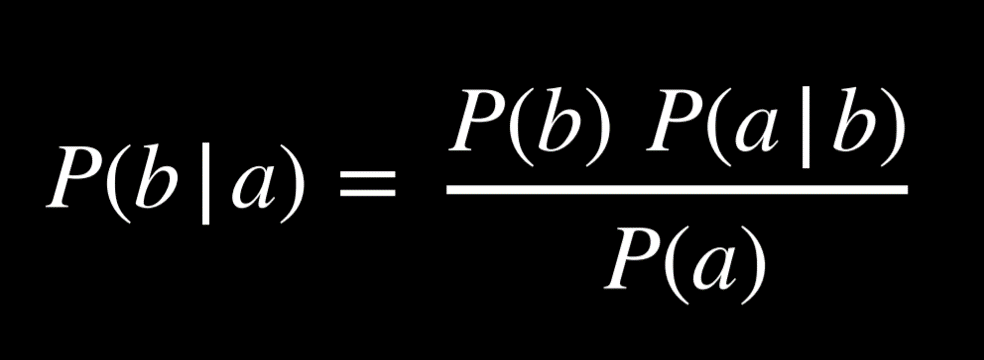
其中 b 代表情绪,a 代表那句话。
举个例子,”我的孙子爱它“,如果想计算它表达积极情绪的概率,就可以转为计算它们的联合概率,即。
$$P(正向,“我的”,“孙子”,“爱”,“它”) * P(正向)$$
但是,计算这个联合概率很复杂,因为每个单词的概率都取决于它前面的单词的概率,它要求我们计算 P(正) * P(“我的” | 正) * P(“孙” | 正,“我的”) * P(爱 | 正,“我的”,“孙子”) * P(“它” | 正,”我的“,“孙子”,“爱”)。
不过我们可以不考虑语法,也就是假设每个单词的概率独立于其他单词,也能得到不错的效果。
$$P(积极) * P(“我的” | 积极) * P(“孙子” | 积极) * P(“爱” | 积极) * P(“它” | 积极)$$
这并不难计算,其中 P(正) = 所有正样本数除以总样本数,P(“爱” | 正向) 等于带有单词 “爱” 的正样本数除以正样本数,具体如下。

朴素贝叶斯的优势在于,它对一种句子中出现频率高于另一种句子的单词敏感。在我们的例子中,“爱” 这个词在肯定句中出现的频率要高得多,这使得整个句子更有可能是正面的而不是负面的。
单词表示
独热编码
在独热编码中,每个单词都用一个向量表示,该向量由与我们拥有的单词一样多的值组成,除了向量中等于 1 的单个值外,所有其他值都等于 0。
例如,“他写了一本书” 可以表示为四个向量。
- [1, 0, 0, 0](他)。
- [0, 1, 0, 0](写了)。
- [0, 0, 1, 0](一本)。
- [0, 0, 0, 1](书)。
但是当单词多起来之后,我们就很难用这种方法来表示了。
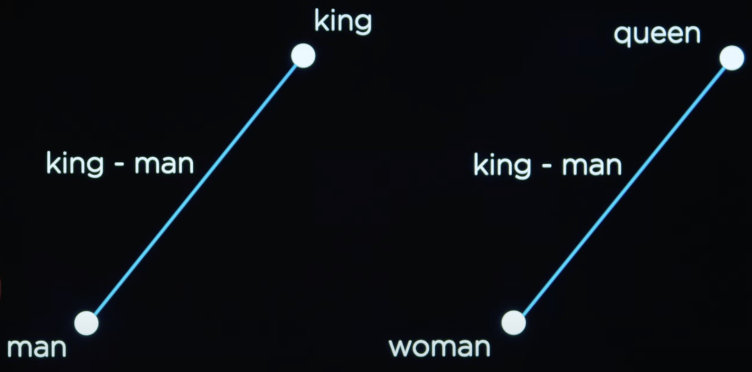
而且这种方法有个最致命的问题,就是没办法表示一些类似的单词,比如早饭和中饭两个词之间的距离,肯定应该比早饭和游泳之间的距离短。
再比如说如下图,男人到国王的距离应该是与女人到皇后的距离相等的,但是这些都不能在独热编码中体现出来。
Word2Vec
所以我们应该用更加小的维度,将它们表示成几个不同的数字,比如上面的例子,我们可以重新表示为。
- [-0.34, -0.08, 0.02, -0.18, …](他)。
- [-0.27, 0.40, 0.00, -0.65, …](写了)。
- [-0.12, -0.25, 0.29, -0.09, …](一本)。
- [-0.23, -0.16, -0.05, -0.57, …](书)。
Word2Vec 是一种用于生成单词的分布式表示的算法。它通过 Skip-Gram 架构来实现这一点,Skip-Gram 架构是一种神经网络架构,用于在给定目标词的情况下预测上下文。
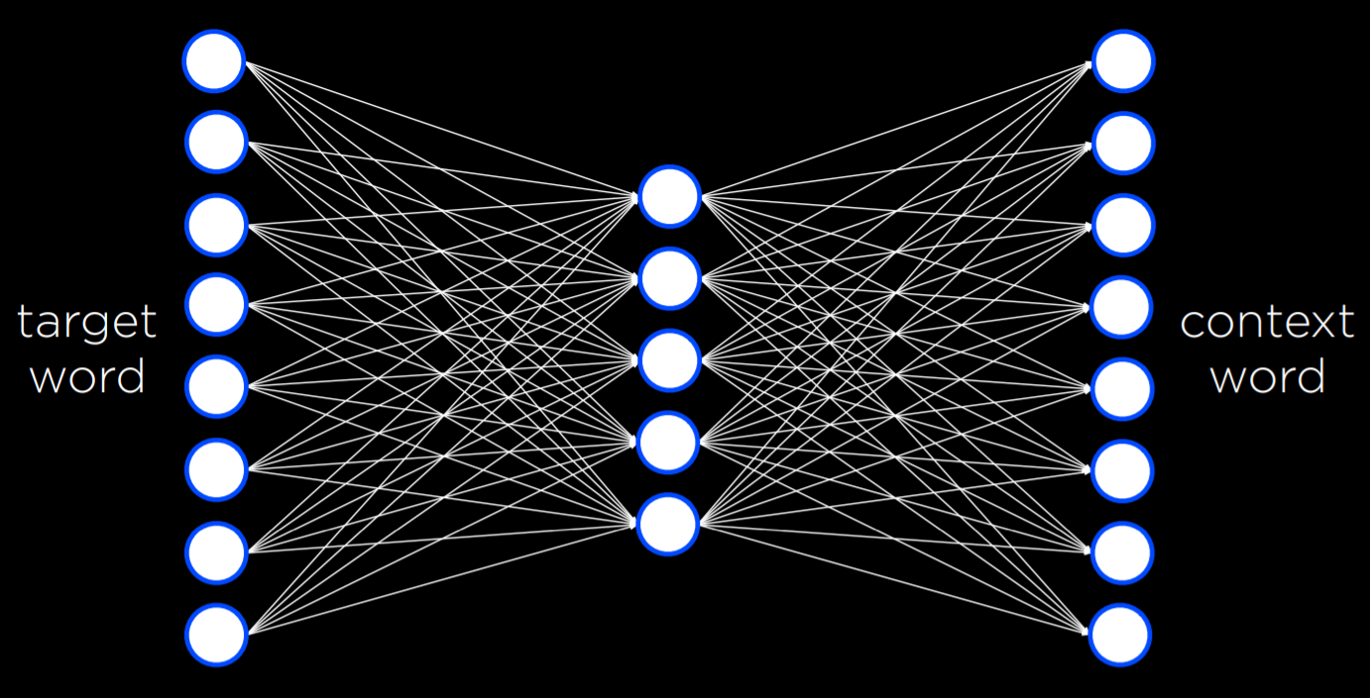
在此体系结构中,神经网络的每个目标单词都有一个输入单元。较小的单个隐藏层(例如50/100个单位)将生成表示单词的分布式表示的值,输出层将生成可能出现在与目标单词相似的上下文中的单词,而 Word2Vec 就是整个网络的副产物,它可以将任意一个单词表示成特定的向量。
后记
你能觉得关键看完还是不知道 AI 怎么就理解语意了,但是其实有上面的知识就足够了。
AI 已经能够补全你的想法了,也能够知道相似词,甚至能够回答问题(这个明天讲),所以说它理解了吗?我也不清楚,学界也还有争论,但是至少看上去理解了。
 wechat
wechat alipay
alipay