
Neural Networks篇(一),理解模型的结构并实战
前言
上一篇说这篇要完善狼人杀的代码来着,后来感觉干脆等 Language 篇讲完再做会比较好一些。
所以今天就继续来讲神经网络,完整代码见 https://github.com/zong4/AILearning。
模型结构
一维输入
神经网络在我眼里其实本质是泰勒展开,即所有连续函数都可以用一长串多项式来表示。
那至于不连续函数就需要请出激活函数了,通过激活函数我们可以做到截断一些函数再组合,从而实现特殊的图案。
给大家看个好玩的,如下图,我们现在要搭建一个模型来完成这个分类任务。
那目前我们只有输入层和输出层,也就是机器学习,很明显它没有办法把中间的蓝色包裹起来,只能划出一条斜线。

现在我们试着加入一层隐藏层,也就是中间层,可以看到当中间层有三个节点时,它就已经能完成分类任务了。
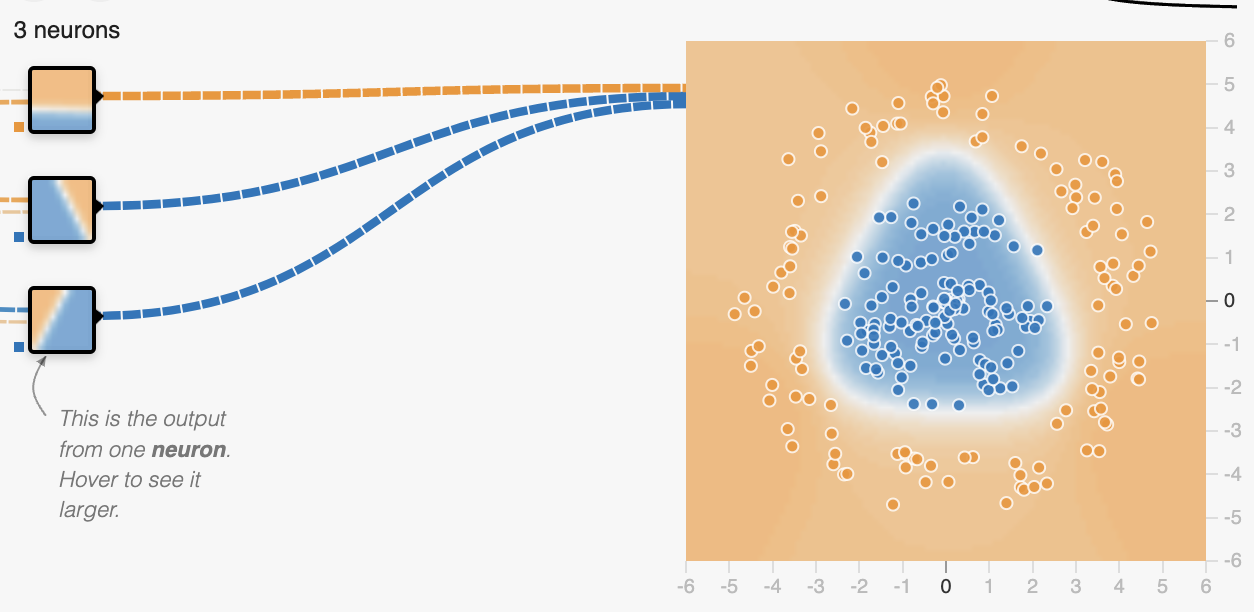
这三个节点的输出分别是三条线,如下。
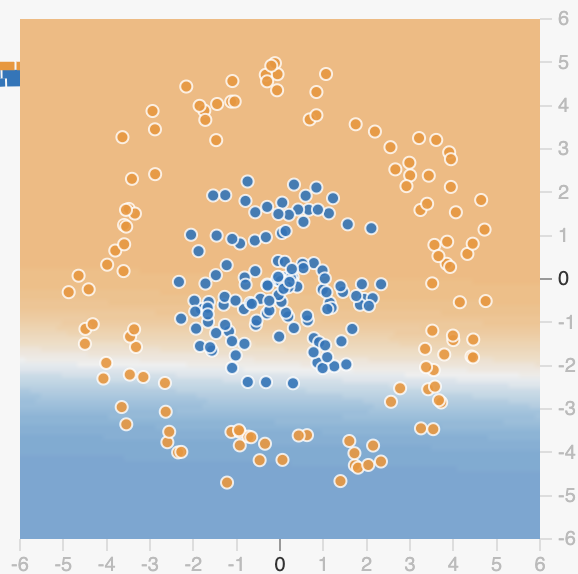
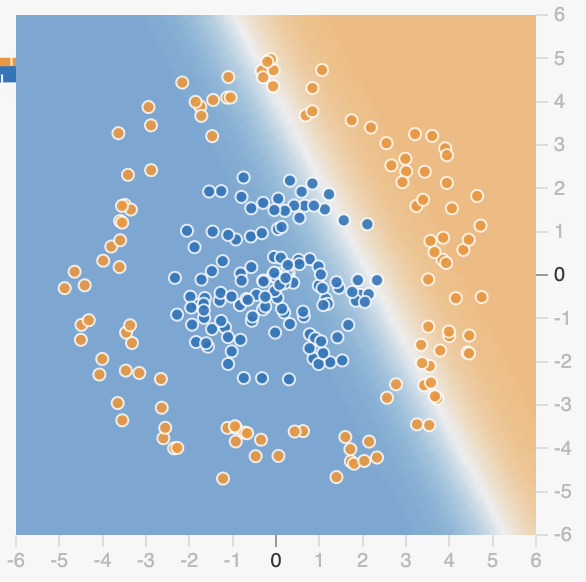
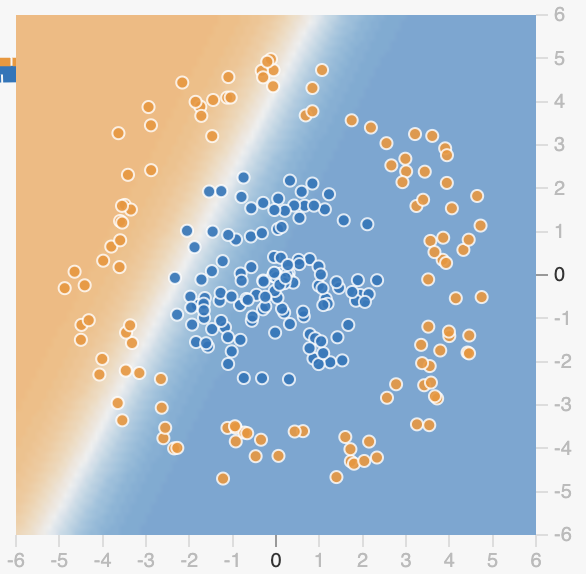
这就是我上面所说的通过激活函数配合多项式来实现一些特殊图案,至此我们就理解了为什么 AI 能处理所有的一位数据,接下来我们来看看多维数据。
多维输入
多维数据中首当其冲的就是图像了,那我们该如何让 AI 处理这二维数据呢,或者说我们该如何讲二维数据转换成一维数据呢?
其实很简单,我们只要把二维图像展开不就好了。
但是这有个问题就是二维图像,很多数据是冗余的,比如我们要识别物体,我们根本就不需要它的颜色数据,因此我们需要卷积层以及池化层。
通过卷积层我们可以让下面第一张图转换成第二张,是不是很神奇,我们竟然将图像的边缘信息提取了出来。

紧接着通过池化层,我们可以压缩图像一倍的信息,再重复这两步,我们就可以将图像的像素点压缩到可接受范围内,从而展平为一维数据进行处理,如下图。
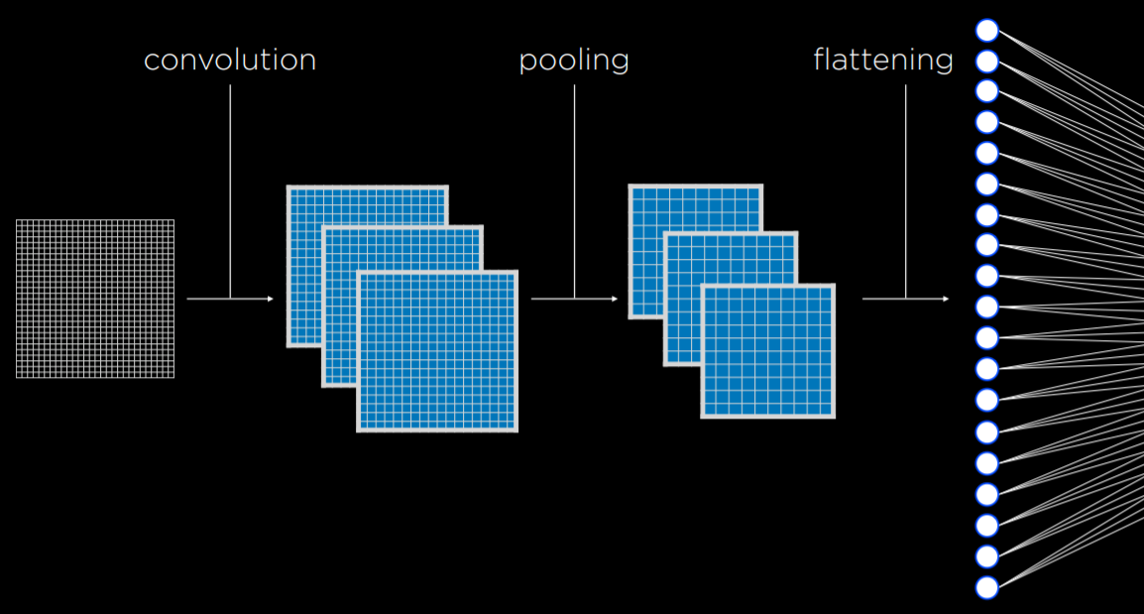
二维既然有二维卷积,那三维也会有三维卷积了,所以更高维我就不介绍了,而且也一般见不到,因为一般再往上就是时间维度了。
序列输入
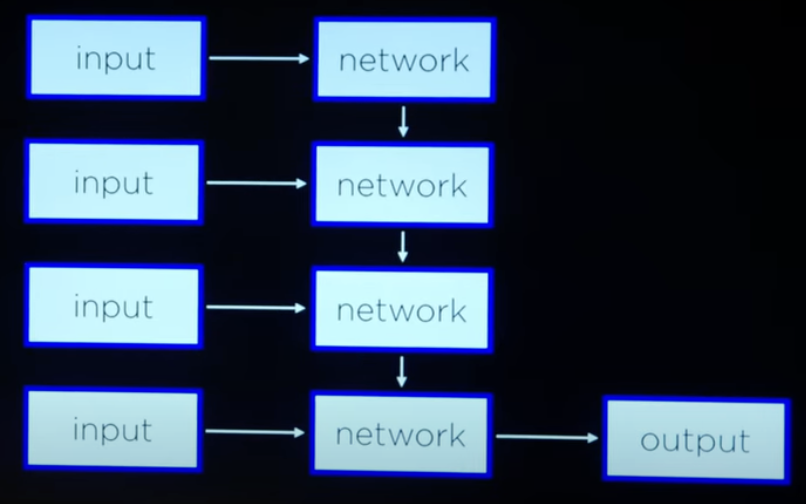
带时间维度的数据我们都会称呼其为序列数据,这也意味着会有完全不同的处理方式,如下图。
再给大家看一看之前的模型长什么样。

可以看到多了很多的 Input 和 Network。
这一列 Input 就代表了按照时间顺序依次输入的信息,而其对应的 Network 则每次从之前的 Network 中收集信息并学习新的信息,最后由最后一个 Network 输出完整的信息。
那其实还有一种序列数据就是语言,语言中的每一句话都是相连的。
其实说白了,什么是序列数据,有上下文的就是。
序列输出
OK,来看看最后一种模型,就是它的输出是语言,或者直白点它的输出有上下文。
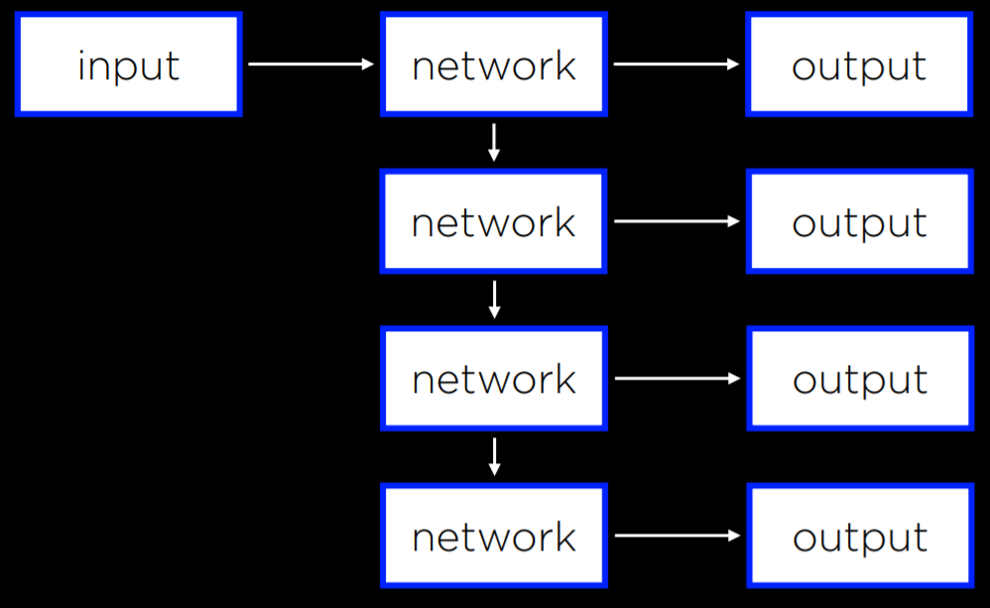
这应该很好理解吧,就不多赘述了。
训练模型
讲完了模型结构来看看模型怎么训练的。
反向传播
因为我们需要根据结果来调整我们的模型,才能让模型变得更好,反向传播变应运而生了。
要想做到反向传播首先需要损失函数来判断预测的结果和真实结果的差距,然后再通过梯度下降计算各个节点的权重应该如何变化,那具体是怎么实现的呢?
首先的话,需要先计算出损失函数,那对于任何结果,我们可以计算出损失值如下。
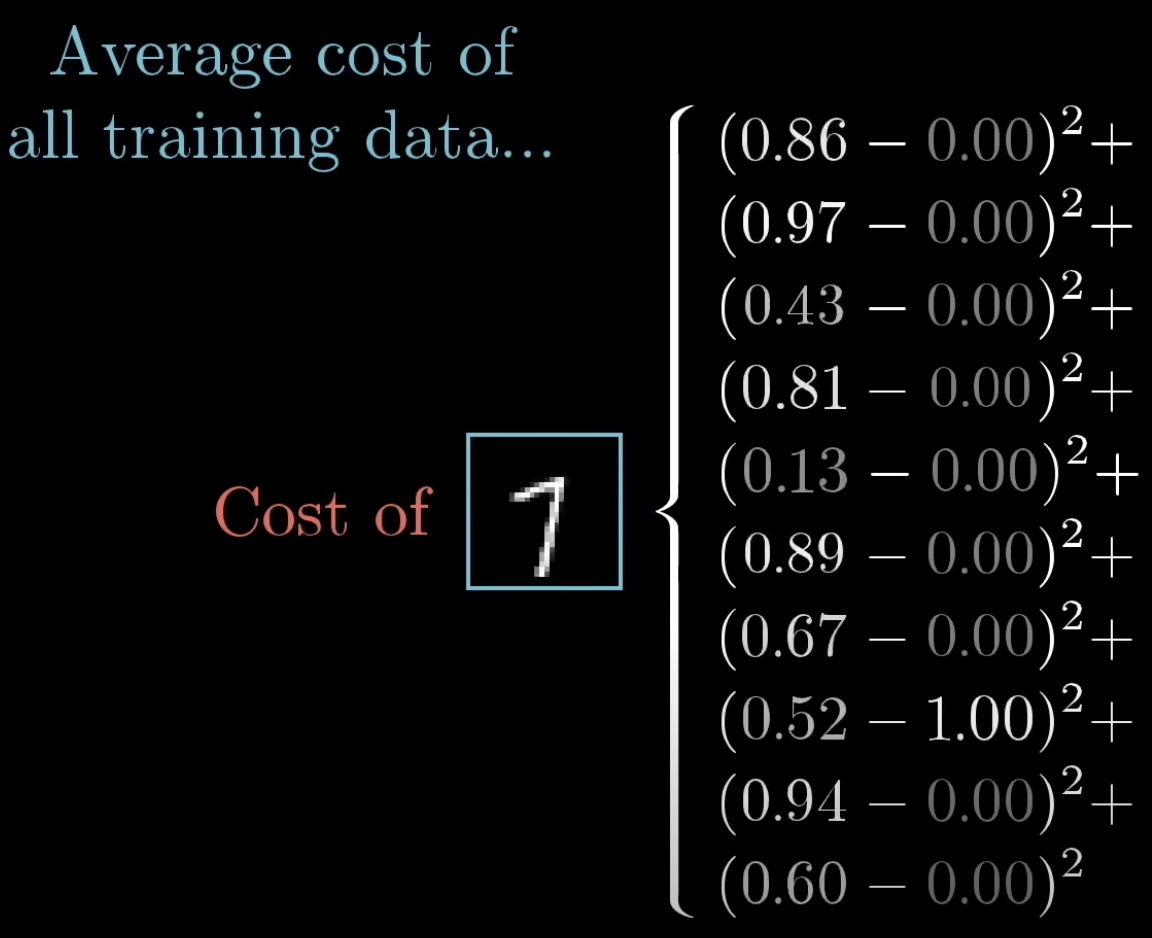
其中左边那一列数据是当权重取到特定值得结果,如果不取特定值,而是将其转换成节点的公式(如下),我们就可以推出复杂的公式。
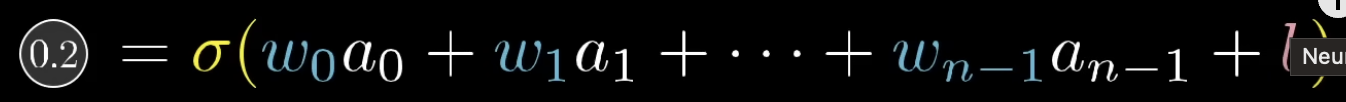
然后求每个权重的偏导数,我们就可以知道它的调整方向,具体步长,一般是初始就设定的,或者像退火算法一样越来越短。
但是如果每算一个结果就调整一次,不仅麻烦,而且结果也可能过拟合,所以我们可以把数据集分成好几个 batch,每个batch更新一次,如下。
Dropout层
这就类似于深度搜索里的剪枝操作,每次计算时,丢掉一些神经元,防止模型过拟合,提高泛化能力。
交通信号灯分类
数据集的话在这 https://cdn.cs50.net/ai/2023/x/projects/5/gtsrb.zip,然后我们主要来讲一下模型,其他东西都跟上一篇差不多。
卷积层就是用来提取特征的,因为你权重的初始时随机的,也就是说它们的梯度下降方向也是不同的,所以在计算时就很容易出现不同的特征,这边就在第一层提取出32种特征。
池化层就是用来压缩的,毕竟都提取出32种特征了,图像还要这么大干嘛,变小一些,专注于局部特征就好。
最后是全连接层,这里就相当于将所有局部特征组合成128个大特征,然后再组合成43种信号。
大家先看看流程图再看代码。
1 | def get_model(): |
其中 model.compile() 里是模型用的一些优化器,损失函数和评估指标,大家可以自行了解。
后记
看着其实还是挺简单的对吧,毕竟这模型就这么小,以后做大的就复杂咯。
 wechat
wechat alipay
alipay