deftransition_model(corpus, page, damping_factor): """ Return a probability distribution over which page to visit next, given a current page. With probability `damping_factor`, choose a link at random linked to by `page`. With probability `1 - damping_factor`, choose a link at random chosen from all pages in the corpus. """ # Create a dictionary to store the probability distribution probability_distribution = {} # If the page has no links, return a probability distribution that chooses randomly from all pages iflen(corpus[page]) == 0: for page in corpus: probability_distribution[page] = 1 / len(corpus) return probability_distribution # Calculate the probability of choosing a link at random linked to the page for linked_page in corpus[page]: probability_distribution[linked_page] = damping_factor / len(corpus[page]) # Calculate the probability of choosing a link at random from all pages for page in corpus: probability_distribution[page] = (1 - damping_factor) / len(corpus) return probability_distribution
defsample_pagerank(corpus, damping_factor, n): """ Return PageRank values for each page by sampling `n` pages according to transition model, starting with a page at random. Return a dictionary where keys are page names, and values are their estimated PageRank value (a value between 0 and 1). All PageRank values should sum to 1. """
# Create a dictionary to store the number of times each page is visited page_visits = {page: 0for page in corpus} # Choose a random page to start current_page = random.choice(list(corpus.keys())) # Visit n pages for i inrange(n): page_visits[current_page] += 1 # Get the probability distribution for the current page probability_distribution = transition_model(corpus, current_page, damping_factor) # Choose the next page based on the probability distribution current_page = random.choices(list(probability_distribution.keys()), weights=probability_distribution.values(), k=1)[0] # Calculate the PageRank values page_rank = {page: page_visits[page] / n for page in corpus} return page_rank
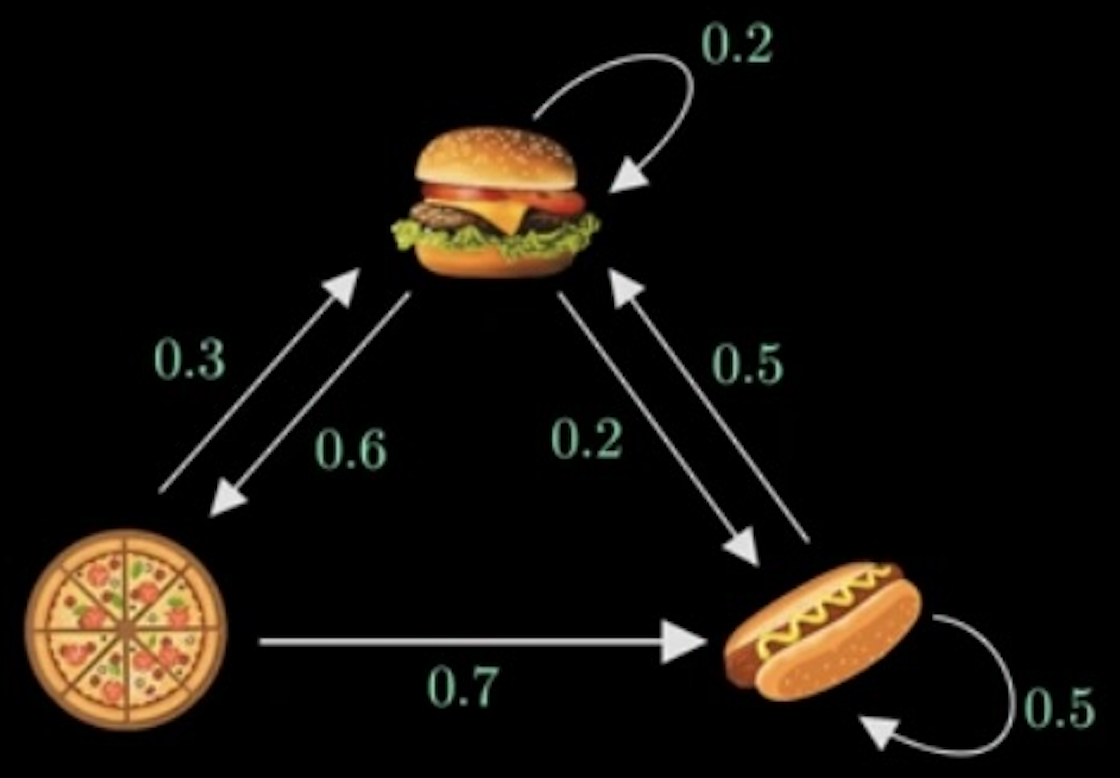
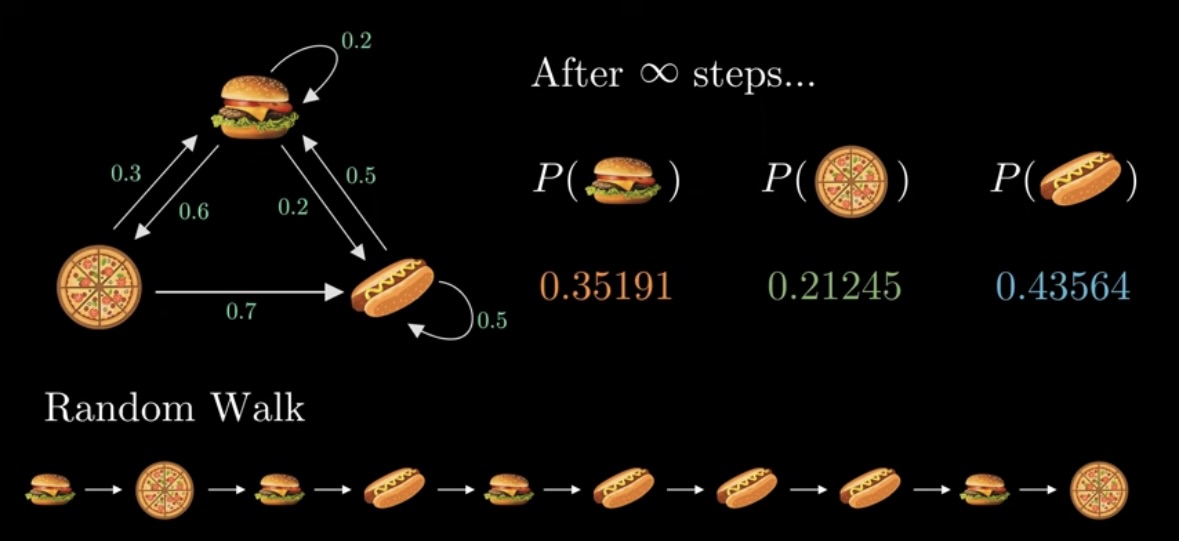
其中 transition_model 就是我们的冲浪逻辑,而 sample_pagerank 中,通过记录 n 次冲浪时浏览的网站来给出相应的 Page Rank。
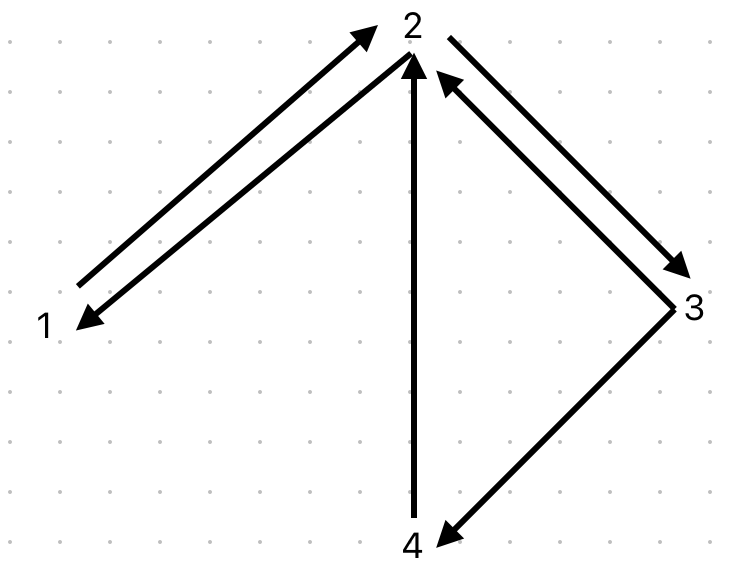
defiterate_pagerank(corpus, damping_factor): """ Return PageRank values for each page by iteratively updating PageRank values until convergence. Return a dictionary where keys are page names, and values are their estimated PageRank value (a value between 0 and 1). All PageRank values should sum to 1. """ # Create a dictionary to store the PageRank values page_rank = {page: 1 / len(corpus) for page in corpus} # Create a dictionary to store the new PageRank values new_page_rank = {page: 0for page in corpus} # Create a boolean variable to check if the PageRank values have converged converged = False # Iterate until the PageRank values converge whilenot converged: # Calculate the new PageRank values for page in corpus: new_page_rank[page] = (1 - damping_factor) / len(corpus) for linking_page in corpus: if page in corpus[linking_page]: new_page_rank[page] += damping_factor * page_rank[linking_page] / len(corpus[linking_page]) # Check if the PageRank values have converged ifall(abs(new_page_rank[page] - page_rank[page]) < 0.001for page in corpus): converged = True # Update the PageRank values page_rank = new_page_rank.copy() return page_rank

 wechat
wechat alipay
alipay