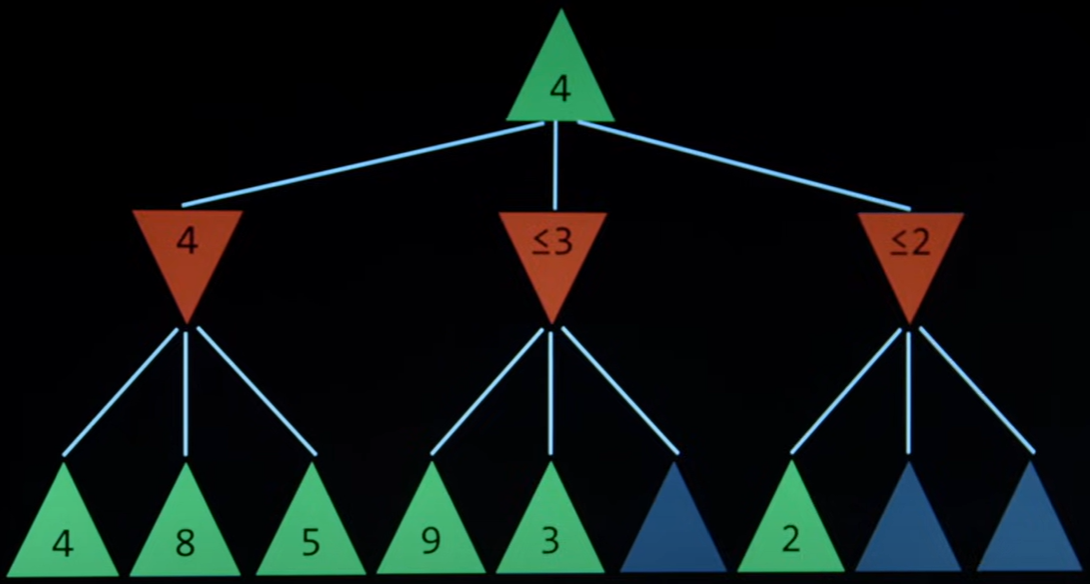
defminimax(board, depth, player): if player == 'X': best = [-1, -1, -10] else: best = [-1, -1, 10] if depth == 0: score = evaluate(board) return [-1, -1, score] for cell in empty_cells(board): x, y = cell[0], cell[1] board[x][y] = player score = minimax(board, depth - 1, 'O'if player == 'X'else'X') board[x][y] = ' ' score[0], score[1] = x, y if player == 'X': if score[2] > best[2]: best = score else: if score[2] < best[2]: best = score return best
defevaluate(board): for row in board: if row.count('X') == 3: return10 if row.count('O') == 3: return -10 for col inrange(3): if board[0][col] == board[1][col] == board[2][col] == 'X': return10 if board[0][col] == board[1][col] == board[2][col] == 'O': return -10 if board[0][0] == board[1][1] == board[2][2] == 'X'or board[0][2] == board[1][1] == board[2][0] == 'X': return10 if board[0][0] == board[1][1] == board[2][2] == 'O'or board[0][2] == board[1][1] == board[2][0] == 'O': return -10 return0
defempty_cells(board): cells = [] for i inrange(3): for j inrange(3): if board[i][j] == ' ': cells.append([i, j]) return cells
------------- | | | | | | | | | | | | ------------- Player X ------------- | X | | | | | | | | | | | ------------- Player O ------------- | X | | | | | O | | | | | | ------------- Player X ------------- | X | X | | | | O | | | | | | ------------- Player O ------------- | X | X | O | | | O | | | | | | ------------- Player X ------------- | X | X | O | | | O | | | X | | | ------------- Player O ------------- | X | X | O | | O | O | | | X | | | ------------- Player X ------------- | X | X | O | | O | O | X | | X | | | ------------- Player O ------------- | X | X | O | | O | O | X | | X | O | | ------------- Player X ------------- | X | X | O | | O | O | X | | X | O | X | -------------

 wechat
wechat alipay
alipay